FSB Feasibility Study on Approaches to Aggregate OTC Derivatives Data - February 2014
CFTC

























































































































































Description
Consultation Paper
Feasibility study on approaches
to aggregate OTC derivatives data
4 February 2014
.
. Preface
Feasibility study on approaches to aggregate
OTC derivatives trade repository data
Public consultation paper
G20 Leaders agreed, as part of their commitments regarding OTC derivatives reforms, that all
OTC derivatives contracts should be reported to trade repositories (TRs). The FSB was
requested to assess whether implementation of these reforms is sufficient to improve
transparency in the derivatives markets, mitigate systemic risk, and protect against market
abuse.
A good deal of progress has been made in establishing the market infrastructure to support the
commitment that all contracts be reported to TRs. However, the data will be reported to
multiple TRs located in a number of jurisdictions. The FSB therefore requested further study
of how to ensure that the data reported to TRs can be effectively used by authorities, including
to identify and mitigate systemic risk, and in particular through enabling the availability of the
data in aggregated form.
The FSB, in consultation with the Committee on Payment and Settlement Systems (CPSS) and the International Organization of Securities Commissions (IOSCO), will then make a decision on whether to initiate work to develop a global aggregation mechanism and, if so, according to which type of aggregation model and which additional policy actions may be needed to address obstacles. The attached public consultation paper responds to the request by the FSB for a feasibility study that sets out and analyses the various options for aggregating OTC derivatives TR data. The draft has been prepared by a study group set up by the FSB and composed of experts from member organisations of CPSS and IOSCO and other organisations with roles in macroprudential and microprudential surveillance and supervision. The paper discusses the key requirements and challenges involved in the aggregation of TR data, and proposes criteria for assessing different aggregation models. Following this public consultation and further analysis by the study group, a finalised version of the report, including recommendations, will be submitted to the FSB in May 2014 for approval and published thereafter. The public consultation paper examines the three broad types of model for an aggregation mechanism: a physically centralised model; a logically centralised model; and the collection and aggregation by authorities themselves of raw data from TRs. Within these three broad types of model, a variety of detailed alternatives exist that would provide differing levels of sophistication of service.
These alternatives would need to be examined further in the final report in May and in any follow-on work that may be commissioned to take forward one of models following this feasibility study. i . The study is focusing on the feasibility of options for data aggregation in the current regulatory and technological environment and given the existing (and planned) global configuration and functionality of TRs. The aggregation options are being considered on the basis that they would complement, rather than replace, the existing operations of TRs and authorities’ existing direct access to TR data. The paper analyses the key factors and challenges associated with the three models, taking into account the range of needs of authorities for aggregated data across TRs and focusing on those considerations that are most relevant to the potential choice of model. It divides these considerations into two types: • legal considerations, including those relating to submission of data to the aggregation mechanism, access to the mechanism, and governance of the mechanism: and • data and technology considerations, including those related to data standardisation and harmonisation, data quality, information security, and other technological considerations. Based on this analysis, the paper proposes a set of criteria to be used in order to provide a common and systematic structure for the assessment of the options in the final report. The paper does not at this stage propose draft conclusions or recommendations for the final report. The FSB wishes to have feedback via this public consultation process on these considerations and criteria before proceeding to the assessment itself.
The feedback received will inform the further analysis by the FSB study group regarding the aggregation solutions, the constraints, and the methodology to be followed for the assessment. The FSB invites comments in particular on the following questions: 1. Does the analysis of the legal considerations for each option cover the key issues? Are there additional legal considerations - or possible approaches that would mitigate the considerations - that should be taken into account? 2. Does the analysis of the data and technology considerations cover the key issues? Are there additional data and technology considerations - or possible approaches that would mitigate those considerations - that should be taken into account? 3.
Is the list of criteria to assess the aggregation options appropriate? 4. Are there any other broad models than the three outlined in the report that should be considered? 5. The report discusses aggregation options from the point of view of the uses authorities have for aggregated TR data.
Are there also uses that the market or wider public would have for data from such an aggregation mechanism that should be taken into account? Responses should be sent by Friday 28 February 2014 to fsb@bis.org with “AFSG comment” in the e-mail title. Responses will be published on the FSB’s website unless respondents expressly request otherwise. ii . Table of Contents Page Executive Summary ................................................................................................................... 3 Introduction ................................................................................................................................ 3 Chapter 1 – Objectives, Scope and Approach ............................................................................ 5 1.1 Objective of the Study ................................................................................................
5 1.2 Scope of the Study...................................................................................................... 5 1.3 Aggregation Models Analysed ................................................................................... 5 1.4 Preparation of the Study .............................................................................................
8 1.5 Definition of Data Aggregation.................................................................................. 8 1.6 Assumptions ............................................................................................................... 9 Chapter 2 – Stocktake of Existing Trade Repositories ..............................................................
9 2.1 TR reporting implementation and current use of data................................................ 9 2.2 Available data fields and data gaps .......................................................................... 11 2.3 Data standards and format ........................................................................................
11 2.4 Legal and privacy issues .......................................................................................... 12 Chapter 3 – Authorities’ Requirements for Aggregated OTC Derivatives Data ..................... 12 3.1 3.1 Data Needs .........................................................................................................
12 3.2 Aggregation Minimum Prerequisites ....................................................................... 14 3.3 Further aggregation requirements ............................................................................ 17 Chapter 4 – Legal Considerations ............................................................................................
19 4.1 Types of existing legal obstacles to submit/collect data from local trade repositories into an aggregation mechanism ............................................................................................ 21 4.2 Legal challenges to access to TR data ...................................................................... 23 4.3 Legal considerations for the governance of the system ...........................................
24 Chapter 5 – Data & Technology Considerations ..................................................................... 29 5.1 The Impact of the Aggregation Option on Data and Technology ............................ 29 5.2 Data aggregation and reporting framework .............................................................
30 5.3 Data reporting ........................................................................................................... 30 5.4 Principles of data management to facilitate proper data aggregation ...................... 31 5.5 Principles of data management regarding the underlying data ................................
31 5.6 Principles of data management regarding the technological arrangements ............. 38 1 . Chapter 6 – Assessment of Data Aggregation Options ............................................................ 40 Chapter 7 – Concluding Assessment ........................................................................................ 42 Appendix 1: Feasibility study on approaches to aggregate OTC derivatives data .................. 43 Appendix 2: Summary of the outreach workshop ...................................................................
51 Appendix 3: Extract from the Access Report (Table 6.2) ....................................................... 62 Appendix 4: Data Elements ..................................................................................................... 65 Appendix 5: Glossary of Terms and Abbreviations ................................................................
67 Appendix 6: Members of Workshop ....................................................................................... 70 Appendix 7: List of References ............................................................................................... 73 2 .
Executive Summary This section will contain a summarised version of the entire report targeted for a quick and comprehensive read [to be added after consultation]. Introduction G20 Leaders agreed, as part of their commitments regarding OTC derivatives reforms, that all OTC derivatives contracts should be reported to trade repositories (TRs). The FSB was requested to assess whether implementation of these reforms is sufficient to improve transparency in the derivatives markets, mitigate systemic risk, and protect against market abuse. A good deal of progress has been made in establishing the TR infrastructure to support the commitment that all contracts be reported. Currently, multiple TRs operate, or are undergoing approval processes to do so, in a number of different jurisdictions. The requirements for trade reporting differ across jurisdictions.
The result is that TR data are fragmented across many locations, stored in a variety of formats, and subject to many different rules for authorities’ access. The data in these TRs will need to be aggregated in various ways if authorities are to obtain a comprehensive and accurate view of the global OTC derivatives markets and to meet the original financial stability objectives of the G20 in calling for comprehensive use of TRs. The FSB, CPSS and IOSCO have identified the need for further study of how to ensure that the data reported to TRs can be effectively used by authorities, including to identify and mitigate systemic risk, and in particular through enabling the availability of the data in aggregated form. The FSB set up a group - the Aggregation Feasibility Study Group (AFSG) to study the feasibility of several options to produce and share the types of global aggregated TR data that authorities need to fulfil their mandates and to monitor financial stability, taking into account legal and technical issues.
The FSB’s terms of reference for the study are attached as Appendix 1. This draft report takes as a starting point existing international guidance and recommendations relating to TRs, including those contained in the January 2012 CPSSIOSCO report on OTC derivatives data reporting and aggregation requirements (“Data Report”) and the August 2013 CPSS-IOSCO report on authorities’ access to TR data (“Access Report”). It has also made use of the semi-annual FSB progress reports on the implementation of OTC derivatives market reforms, including on the implementation of comprehensive trade reporting requirements. Structure of the Report The report is structured as follows. Chapter 1 lays down the objectives, scope and approach followed by the feasibility study. Chapter 2 makes a brief stock-take of the current status of TR implementation, including the current and planned global configuration of TRs, in order to provide background on the scale and scope of the aggregation challenges. 3 . Chapter 3 summarises the different types of requirements of authorities for aggregated OTC derivatives data, focusing in particular on the minimum pre-requisites for aggregation in order that the data are useable by authorities to fulfil their various mandates. Chapter 4 describes the legal and policy considerations, concerning submission of and access to data and governance of the aggregation mechanism, that are relevant to the choice of aggregation model. Chapter 5 discusses the data and technology considerations associated with meeting authorities’ requirements for aggregated data under the different choices of model. Chapter 6 presents the criteria for the assessment of the options derived from the discussion in Chapters 3, 4 and 5, and (to be drafted for the final version of the report following public consultation) the assessment of the pros and cons of the different aggregation options against those criteria. Chapter 7 (to be drafted for the final version of the report following the public consultation) will conclude with the overall recommendations of the study, as well as pointing to policy areas that might need further attention from the FSB, standard setters or jurisdictions, and areas where further study may be needed. This consultative draft report has been prepared by the AFSG and approved for publication by the FSB. The FSB invites comments on the analysis contained in this consultative report and in particular on the following points: 1. 2. 3. 4. 5. Does the analysis of the legal considerations for each option cover the key issues? Are there additional legal considerations - or possible approaches that would mitigate the considerations - that should be taken into account? Does the analysis of the data and technology considerations cover the key issues? Are there additional data and technology considerations - or possible approaches that would mitigate those considerations - that should be taken into account? Is the list of criteria to assess the aggregation options appropriate? Are there any other broad models than the three outlined in the report that should be considered? The report discusses aggregation options from the point of view of the uses authorities have for aggregated TR data. Are there also uses that the market or wider public would have for data from such an aggregation mechanism that should be taken into account? Responses should be sent by Friday 28 February 2014 to fsb@bis.org with “AFSG comment” in the e-mail title. Responses will be published on the FSB’s website unless respondents expressly request otherwise. The feedback received will be taken into account in the finalised version of the report, which will be provided to the FSB in May 2014 and subsequently published by the FSB. 4 .
1. Chapter 1 – Objectives, Scope and Approach 1.1 Objective of the Study The goal of this feasibility study is to set out and analyse the various broad options for aggregating TR data for use by authorities in effectively meeting their respective mandates. The FSB, in consultation with CPSS and IOSCO, will then make a decision on whether to initiate work to develop a global aggregation mechanism and, if so, according to which type of aggregation model and which additional policy actions may be needed to address obstacles. The report is structured so that the final version in May will provide the relevant information for senior policy-makers to be able to make the above decisions, and to inform both senior policy-makers and the public about the analysis supporting that information. 1.2 Scope of the Study For each option, the final version of the report will: • set out the key steps necessary to develop and implement the option, • review the associated legal and technical issues, and • provide a description of the strengths and weaknesses of the option, taking into account the types of aggregated data that authorities may require and the uses to which authorities might put the data. The study is intentionally high-level in approach, comparing the effectiveness of the broad types of options that could be used in meeting the G20 goal that authorities are able to have a global view of the OTC derivatives markets. It does not attempt to analyse the specific technological choices of hardware and software, or define the specific legal and governance requirements. At this early stage of the analysis of the options, with so many elements of the scope and scale of the exercise still undefined, it is not possible to estimate the costs of the different options. The report includes instead a qualitative analysis of the relative complexity of the different options.
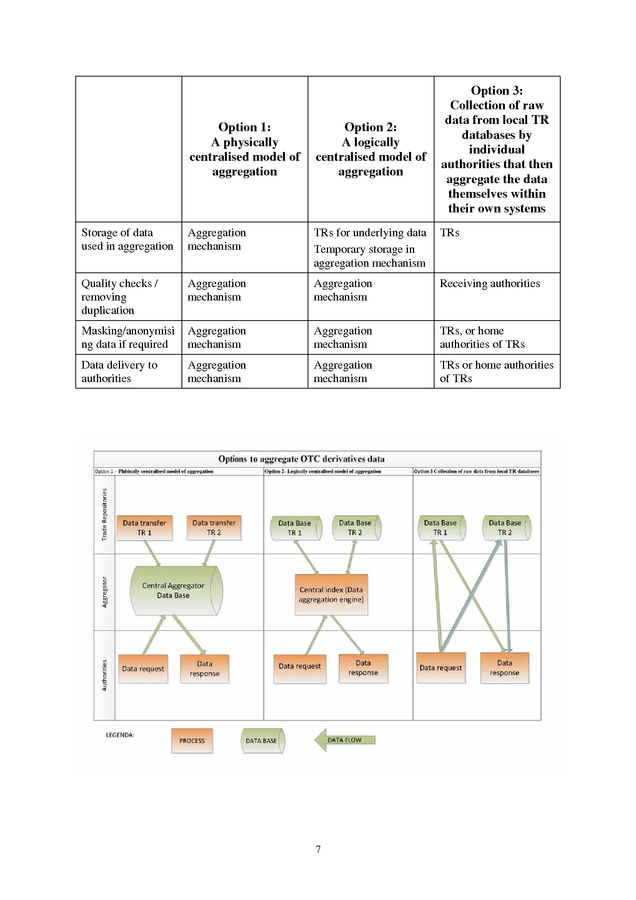
More detailed work on such issues is expected to take place in any follow-on work that may be commissioned by policy-makers. 1.3 Aggregation Models Analysed The main options for aggregating TR data explored by this study are: Option 1. A physically centralised model of aggregation. This model would feature a central database where required transaction and (if needed and available) position and collateral data would be collected from TRs and stored on a regular basis.
The facility housing the database would provide services to report aggregated data to authorities, drawing on the stored underlying transaction, position and collateral details. In order to do so, the facility would perform functions such as data quality checks, removing duplications, and masking or anonymising data as needed. Reports and underlying data would be available to authorities as needed and permitted according to a separate database of individual authorities’ access rights. Option 2.
A logically centralised model of aggregation. This model would feature federated (physically decentralised) data collection and storage of the same types of data as in Option 1. It would not physically collect or store data from TRs (other than temporary local caching 5 . where necessary in the aggregation process). Instead it would rely on a central logical catalogue/index to identify the location of data resident in the TRs, which would assist individual authorities in obtaining data of interest to them. In this model, the underlying data would remain in local TR databases and be aggregated via logical centralisation by the aggregation mechanism, being retrieved on an “as needed” basis at the time the aggregation program is run. 1 Either Option 1 or Option 2 could be implemented with varying degrees of sophistication or service levels, ranging from basic delivery of data in response to each request to - at its most sophisticated – providing additional services beyond basic delivery of data, such as performing quality checks/removing duplications, masking/anonymising data according to the mandate/authorisation of the requester, and aggregating data. The less ambitious versions of Options 1 and 2 would be less complex to implement but would not deliver the full range of services and meet the full range of uses of data that authorities seek in order to meet their mandates.
The final version of this report in May will include an evaluation of the extent to which less ambitious versions of each option could meet the range of user requirements. Option 3. Collection of raw data from local TR databases by individual authorities that then aggregate the data themselves within their own systems. Under this option, there would be no central database or catalogue/index.
All the functions of access rights verification, quality checks, etc., would be performed by the requesting authority and the responding authorities or TRs on a case-by-case basis. Access would be granted based on the rules and legislation applicable to each individual TR. (Option 3 represents the current situation for authorities wishing to aggregate data.
As noted later in this report, truly global and comprehensive data aggregation is not possible under current arrangements as no individual authority or body has comprehensive access to all data in all TRs. Under Option 3, authorities could expand their cross-border access to data from current levels by concluding additional international agreements, but the absence of a centralised aggregation mechanism would seem to preclude the provision of some forms of aggregated data, notably anonymised counterparty-level data.) In this report, the term “aggregation model” is used to refer to any one of the three options above. The term “aggregation mechanism” refers to mechanisms modelled on Option 1 and Option 2 as described above. The table below summarises the division of roles under the different aggregation models in performing the main tasks involved in aggregation, and the accompanying diagram provides a visual representation. 1 Within Option 2, data normalisation and reconciliation can be performed at a centralised or at a decentralised level.
Such sub-options do not fundamentally impact the following analysis and discussion. 6 . Option 3: Collection of raw data from local TR databases by individual authorities that then aggregate the data themselves within their own systems Option 1: A physically centralised model of aggregation Option 2: A logically centralised model of aggregation Storage of data used in aggregation Aggregation mechanism TRs for underlying data Temporary storage in aggregation mechanism TRs Quality checks / removing duplication Aggregation mechanism Aggregation mechanism Receiving authorities Masking/anonymisi ng data if required Aggregation mechanism Aggregation mechanism TRs, or home authorities of TRs Data delivery to authorities Aggregation mechanism Aggregation mechanism TRs or home authorities of TRs 7 . 1.4 Preparation of the Study The design of the study, including the diverse expertise within the AFSG, public consultation on the draft report, publication of the final report, is intended to ensure that the policy-makers have the benefit of a wide range of input before deciding upon the next steps, including which option to pursue. In preparing the draft the AFSG has used a variety of sources, including: • a survey of authorities in FSB member jurisdictions to gather additional information on the OTC derivatives data currently reported to TRs and accessed by authorities, as well as the status of their data aggregation capabilities on both local and global levels; • a workshop to discuss technical and legal issues in relation to the implementation of the alternative options, bringing together members of the AFSG and experts in the data, IT and legal issues involved, from inside and outside the financial industry (see Appendix 2); • existing reports and studies (see full list of references in Appendix 6). 1.5 Definition of Data Aggregation This report uses the Data Report definition of data aggregation “as the organisation of data for a particular purpose, i.e., the compilation of data based on one or more criteria”. Data aggregation may or may not involve logical or mathematical operations such as summing, filtering and comparing. As noted in the Access Report, authorities (depending on their mandates) may require access to aggregated data: • at three levels of depth: 1. Transaction-level (data specific to uniquely identified market participants and transactions) 2. Position-level (gross or netted open positions specific to a uniquely identified participant or pair of participants) 3. Aggregate-level (summed data according to various categories, e.g. by product, maturity, currency, geographical region, type of counterparty, underlier, that are not specific to any uniquely identifiable participant or transaction) • according to a certain level of breadth (in terms of scope of participants and products/underliers) • and according to a certain level of identity (named versus anonymous). 2 An important distinction in terminology therefore exists between the terms “aggregated data” and “aggregate-level data”.
“Aggregated data” are data that have been collected together, but may or may not have been summed; the data could instead be available at transaction-level or position-level. This process of collecting the data together is referred to as “data aggregation”. 2 More detail on the concepts of depth, breadth and identity is available in the Access Report. 8 . “Aggregate-level” data, on the other hand, are data that have been summed according to a certain categorisation so that the data no longer refer to uniquely identifiable transactions. Different authorities (or the same authority at different times) will require access at different levels of depth, breadth and identity for different purposes. The aggregation mechanism will need to be flexible enough to provide authorities with the level of access that they require and are entitled to for these different purposes. Chapter 3 discusses these data needs and how they affect aggregation requirements in more detail. 1.6 Assumptions The study focuses on the feasibility of options for data aggregation in the current regulatory and technological environment and given the existing (and planned) global configuration of TRs. In particular, the study is based on the following assumptions: • that comprehensive reporting of OTC derivatives trades is achieved in the major jurisdictions, in accordance with the G20 commitment, • that TRs operate under their existing functionality and data collection practices, • that the aggregation option being considered would complement, rather than replace, the existing operations of TRs and authorities’ existing direct access to TR data. The study does not set out to propose changes to the data reported to TRs or the data held by TRs unless those changes are necessary or desirable to achieve aggregation.
However, where needed, the study highlights any regulatory or other actions that might be needed in order to enable an option to be implemented or to improve its effectiveness. It notes where relevant improvements in market practices or infrastructure (e.g. introduction of a global Unique Product Identifier (UPI) or Unique Transaction Identifier (UTI)) that would assist the aggregation process, and it recognises where relevant that the aggregation option chosen may have impacts on TRs, market participants, related data providers, authorities and other stakeholders. 2. Chapter 2 – Stocktake of Existing Trade Repositories 2.1 TR reporting implementation and current use of data As indicated in the FSB’s sixth progress report on the implementation of OTC derivatives market reforms, 3 22 TRs in 11 jurisdictions are, or have announced that they will be, operational.
It is not anticipated that TRs will be located in all jurisdictions but rather that regulatory frameworks will, in some instances, facilitate reporting of market participants’ transactions to foreign-domiciled TRs that are recognised, registered or licensed locally. At present, the practical availability of TRs is quite uneven among FSB member jurisdictions, with very few TRs authorised to operate in multiple jurisdictions and some jurisdictions requiring that domestic reporting be limited only to TRs run by domestic authorities or operators. In some jurisdictions, firms are only permitted to meet their reporting obligations 3 See FSB sixth progress report on implementation http://www.financialstabilityboard.org/publications/r_130902b.pdf. 9 of OTC derivatives market reforms: .
by reporting to TRs that have been appropriately authorised (or alternatively granted an exemption from being authorised) in the jurisdiction in which the TR is offering services. In these jurisdictions, therefore, participants cannot meet their reporting obligations until relevant TRs have been authorised, recognised, or granted an exemption from a registration or licensing regime. In any given jurisdiction, the number of local TRs eligible for reporting ranges from zero to 11, and overseas TRs from zero to eight. The pace of implementation of TR reporting shows some differences across jurisdictions. In several jurisdictions there is some form of phased implementation, whether by asset classes or by market participant categories (largest financial participants/below threshold, regulated/end user).
By end-2014, a significant number of jurisdictions will have mandatory TR reporting in place for all asset classes. Other jurisdictions are either expected to have mandatory TR reporting in place by 2015 or have not yet set a date for all asset classes. The scope of implementation presents some differences. For instance, while financial institutions are subject to reporting in all jurisdictions, in some jurisdictions non-financial institutions may not be subject to mandatory reporting or some thresholds may be in place.
In some jurisdictions, transactions have to be conducted and booked locally in order to be subject to reporting, while in other jurisdictions transactions conducted locally but not booked locally or not conducted locally but booked locally are also subject to reporting. In some jurisdictions two-sided reporting is required while other jurisdictions have opted for one-sided reporting. In all but one jurisdiction, 4 reporting has to be made to TRs, with reporting to authorities being only a fall-back option when there is no TR in place. The time limit for reporting may also vary across jurisdictions from reporting on the same day, up to T+30, with most jurisdictions applying a reporting limit under T+3. In most jurisdictions where TR reporting requirements are in place, authorities typically have access to the data held in the TRs as consistent with their mandates. However in some jurisdictions, only a subset of authorities has regulatory access based on the current regulation in place.
In other jurisdictions, where TR reporting requirements are not yet in place, access is provided on a voluntary basis. These differences reflect the different pace of TR legislation implementation across jurisdictions. Authorities usually receive the data based on a specific format according to their respective mandate (with the format differing across authorities) while in some jurisdictions authorities have continuous online access to TRs. Most authorities have access to data based on several mandates (such as financial stability assessment, micro-prudential supervision, and market conduct surveillance). Even once reporting requirements are in place in all jurisdictions, no single authority or body will have a truly global view of the OTC derivatives market, even on an anonymised or aggregate-level basis, unless a global aggregation mechanism is developed. 4 In that jurisdiction, reporting to either the TR or authorities is allowed. 10 .
2.2 Available data fields and data gaps The review of data collected by TRs demonstrates that there are strong commonalities on data fields collected across jurisdictions for a number of key economic terms of contracts such as start dates, description of the payment streams of each counterparty, value, option information needed to model value, and execution information such as execution venue name and type. However, some differences in approach remain, including (but not limited to): • the main difference relates to the market value of transactions and collateral or margining information that are mandated for reporting in some jurisdictions, while they are not in other jurisdictions, • the distinction between standardised and bespoke contracts is reported only in one jurisdiction, • execution information is widely reported except the information on whether a trade is price-forming, which is collected only in a few jurisdictions, • clearing information is not widely reported with the name of the CCP being collected only in a few jurisdictions. In some jurisdictions, transactions once cleared must be reported as being modified transactions, while in other jurisdictions, the clearing results in the required reporting of both the termination of the initial transaction and the initiation of new ones. While transaction, product and legal entity identifiers are widely used, it seems that transaction and product identifiers may depend on different taxonomies which would require further details to ensure unicity (for transaction identifiers) and to check for consistency (for product identifiers) before aggregation. 2.3 Data standards and format The review of data standards and formats utilised by the different TRs in collection and storage of OTC derivatives data demonstrated different approaches that were chosen by various jurisdictions and TRs in addressing the G20 reporting requirement implementation. When it comes to the development and maintenance of reporting data standards, different jurisdictions follow different approaches. While a number of jurisdictions provide specific layouts of the fields and files, some do it for all OTC derivatives asset classes while others have different treatment for different asset class products. On the other extreme, a number of jurisdictions have not implemented data standards for TR data at all.
In some cases, jurisdictions have chosen this approach intentionally by relying on relevant internationally accepted communication procedures and standards, while in other cases standards and harmonisation work is being undertaken but is not yet complete. In this context, some jurisdictions suggest the use of an UPI approach as a uniform product data standard for OTC derivatives data reporting in their rules. However, there is currently no internationally accepted UPI standard.
Among jurisdictions that have prescribed standards, they mostly cover credit, currency, equity and interest rate OTC derivatives although the coverage varies from jurisdiction to jurisdiction. Very few jurisdictions have developed data standards for commodity derivatives, particularly the identification of the underlier (and not only the derivative itself, for which the UPI may suffice). 11 . While some do standards development and maintenance on the regulatory level, others outsource that either to TRs or industry associations or similar body. Some authorities use a hybrid model of the above approaches. A number of authorities indicated that they use some proprietary data items such as Reference Entity Database (RED) Codes 5 in their reporting requirements. However, it was noted that the proprietary licensed data standards seem to be used only for reporting of credit derivatives. The application of tagging standards also varies significantly among jurisdictions yet, in general, only a minority of authorities decided to implement data tagging standards for the OTC derivatives reporting. 2.4 Legal and privacy issues As previously pointed out in the FSB progress reports on the implementation of OTC derivatives market reforms, some jurisdictions have privacy laws, blocking statues and other laws that might prevent firms from reporting counterparty information and foreign authorities from reaching the necessary data from TRs. Some of the jurisdictions will address the issues by changing/enacting new legislations, while others continue to work through possible solutions. In most jurisdictions, TRs are permitted to disclose confidential information only to entities that are specified in law or regulation, and generally these entities include only authorities.
In such cases, access to TR data may be provided to third country authorities only if certain conditions are met, including, for example, the conclusion of an international agreement or Memorandum of Understanding (MoU). In several jurisdictions, a local TR may directly transmit data only to national or local authorities. In some of these jurisdictions, foreign authorities may be granted indirect access to the data via national or local authorities, provided certain conditions are met, including, for example, MoUs between national/local and foreign authorities. 3. Chapter 3 – Authorities’ Requirements for Aggregated OTC Derivatives Data 3.1 3.1 Data Needs Both the Data Report and the Access Report broadly outline the potential data needs of authorities and provide guidance for minimum data reporting and access to TRs.
The Data Report also discusses the importance of legal entity identifiers and a product classification system and makes general recommendations on how to achieve adequate aggregation. The Access Report focuses on the access requirements of authorities under different mandates and the procedures that facilitate authorities’ access to TR data. In order to categorise the diverse needs of authorities for aggregated data across TRs, this feasibility study follows the functional approach employed in the Access Report. This approach maps data needs to individual mandates of an authority and their particular objective 5 Unique alphanumeric codes assigned to all reference entities and reference obligations, which are used to confirm trades on trade matching and clearing platforms. 12 .
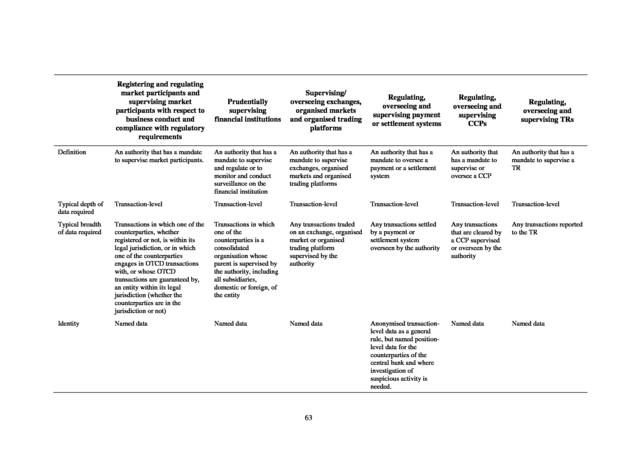
rather than to a type of authority. These mandates may evolve over time. They include (but are not limited to): • Assessing systemic risk, • Performing general macro assessments, • Conducting market surveillance and enforcement, • Supervising market participants, • Regulating, supervising or overseeing trading venues and financial market infrastructures (FMIs), • Planning and conducting resolution activities, • Implementing currency and monetary policy, and lender of last resort, • Conducting research to support the above functions. Appendix 3 describes these mandates as defined in the Access Report. Each mandate has different data needs. The mandates differ considerably in their requirements for data aggregation.
For example, authorities conducting market surveillance and enforcement generally need only data from market participants and infrastructures in their legal jurisdiction. They are frequently also supervisors of the TR where their market participants report, potentially giving them greater access and control of data. In contrast, other mandates would require access to a certain depth and breadth of data across participants and underliers which would not lend itself to a narrow jurisdictional view.
For instance, authorities who assess systemic risk or perform general macro assessments have the need, according to the Access Report, not only for data on counterparties within their jurisdiction but also for anonymised data on counterparties outside their jurisdiction. These data are needed to assess global vulnerabilities and spill-overs between markets. Obtaining these data in a usable format requires the collection of data from many trade repositories in a consistent format with duplicates removed and identifying information masked, as described below.
It also requires the creation of aggregate-level data on exposures. Prudential supervisors similarly need data going beyond their market in order to assess the exposures of firms at a globally consolidated level. 6 For these mandates, a global aggregation solution is essential for providing adequate transparency to the official sector concerning the OTC derivatives market.
Currently, no authority has a complete overview of the risks in OTC derivatives markets or is able to examine the global network of OTC derivatives transactions in depth. The complex set of needs of various authorities calls for an aggregation mechanism providing flexibility and fitted for evolutionary requests as financial markets and products evolve. It is also equally important for such a mechanism to be evolutionary in nature in order to respond 6 Prudential supervisors would need the following aggregated data to assess the soundness of entities operating in multiple jurisdictions: Counterparty exposures to assess the counterparty credit risk; Data on net position, valuation and collateral to assess the market risk of each portfolio of OTC derivative instruments; Data on periodic contractual cash flows in OTC derivatives to be used for assessing overall liquidity risk of the entity. 13 . to evolving needs for aggregated data by authorities. It appears that a key factor differentiating these aggregated data relates to whether they refer to named data or not. To provide authorities with the aggregated data consistent with the Access Report, various types of data aggregation will be necessary to complement the data that authorities may directly access from TRs. Some of the most important processes that are essential for aggregating TR data are described in the following sections. 3.2 Aggregation Minimum Prerequisites The following steps are core to any aggregation of OTC derivatives data for all types of mandates. These steps would apply regardless of the aggregation model used.
Box 1 illustrates the various aggregation steps through some example uses of TR data by authorities with particular mandates. Chapter 5 further expands on technical implementation of these steps. a) User Requirements for Data Harmonisation TR data originate from a wide range of market participants submitting data in a variety of formats over numerous communications channels. TRs themselves have different interpretations of terminologies, reporting specifications and data formats depending on the rules in their jurisdictions and their own choices.
TR data must therefore be transformed into a common and consistent form for use in analysis on an aggregated level. This would be easier if the same interpretations and data standards are implemented across TRs. Where data standards and interpretations are different, harmonising the data is more difficult and perhaps in some cases impossible. Some important examples of necessary harmonisation are: • Need for a consistent interpretation of terminologies (e.g., transaction, position, UPI, whether the quantity of a transaction or of a position is expressed in the number of contracts or their value, etc.), • The standard and format for expressing the terms of a transaction (such as the transaction price, quantity, relevant dates, and terms specific to certain types of securities such as rates, coupons, haircuts, value of the underlying, etc.) and whether a transaction is a price-forming trade, • The identification of trades that are submitted for clearing and the child-trades created as a result.
In some jurisdictions transactions once cleared must be reported as being modified transactions, while in other jurisdictions, the clearing results in the required reporting of both the termination of the initial transaction and the initiation of the new ones (“alpha-beta-trade” issue). b) User Requirements for Concatenation Data necessary for fulfilling authorities’ mandates may be held in several individual TRs in different locations. This is the result of competitive forces as well as regulatory requirements in various jurisdictions. Data are, therefore, physically and logically fragmented.
The current landscape is described in Chapter 2. In order to analyse data, each authority will need, directly or indirectly, legal access and technical connections to each TR containing relevant data. Certain analyses can be 14 . accomplished with partially fragmented data sets. For example, the mandates “Registering and regulating market participants” and “Supervising market participants with respect to business conduct and compliance with regulatory requirements” can be accomplished with data only from the (potentially small) number of TRs where specific market participants report. In contrast, the mandate “Assessing systemic risk” requires data from essentially all TRs and therefore needs a great deal of concatenation. One challenge is how an authority can know which TR holds data relevant to its mandate, given the proliferation of TRs and the various reporting requirements in different jurisdictions. c) User Requirements for Data Cleaning In the numerous stages of data reporting and processing 7 from the origin of the trade, submission to the TR, aggregation, and up to the analysis by the authority, errors could be introduced in the data.
While TRs are required to produce clean data, it might still be necessary for the data to be checked for errors and corrected wherever possible before the aggregation mechanism is capable of delivering meaningful results. d) User Requirements for Removal of Duplicates An important issue inherent in OTC derivatives data is the problem of duplicate transaction records, or “double counting”. Duplicate records could potentially be collected and stored in several TRs. Duplicates might result from the concatenation of data from different TRs. Each party to a given contract might report the event (any “flow event” such as a new trade, an amendment, assignment, etc.) to two (or more) different TRs in the same or different jurisdictions.
For example, Party A might report an event to a TR located in jurisdiction A and Party B might report the same event to a TR located in jurisdiction B. If data from the TR A and the TR B are combined into a single dataset, a record for this single event will appear in the dataset twice. This double-reporting may have been done to comply with local regulations; alternatively, it may have resulted from voluntary reporting practices. For instance, when a transaction is made on an electronic trading venue with an associated TR, the transaction might automatically flow into the venue’s TR, but the counterparty might also choose to report it to another TR so that it can gain a comprehensive view of its transactions through that utility. It is challenging to eliminate duplicate transactions particularly when combining two different datasets, and even more so in the absence of data harmonisation and standardisation.
If the two datasets are simply concatenated, the combined dataset would include duplicate transactions and any measures of exposure or other sums would be biased. If a global system of UTIs were in place, these could be used to match and eliminate the duplicates. If there is no effective UTI, the authority then has the following options: • 7 If the dataset is named or partially anonymised, the analyst (or aggregation mechanism in Options 1 and 2) could develop an approach to eliminate likely duplicates assuming some accepted degree of error (for example, the user could Processing refers to all steps incurred by data along the trade lifecycle, including the amendments to the contract, that in some jurisdictions have to be reported to the TR and thus increase the probability of errors to be introduced in the data. 15 .
define duplicate events as those with the same counterparties, same contract terms, and same transaction date and times). • If the dataset is fully anonymised, i.e., no counterparty information is provided, there is no solution to remove the duplicates. e) User Requirements for Anonymisation Under certain mandates, authorities only have rights to obtain anonymised data and may be legally prevented from obtaining named data. Other mandates additionally necessarily require access to named data, at least for participants and/or underliers located in their respective jurisdictions. There are two ways to anonymise named transaction data: • Records can be fully anonymised, where the counterparty name or public identifier (such as Legal Entity Identifier (LEI)) is redacted. This type of anonymisation is simple and can be performed on different datasets of raw transaction events prior to concatenation.
For example, TR A and TR B can themselves remove counterparty names from their respective datasets before sending to a user third party to combine. It has to be highlighted that once raw transaction event data are fully anonymised, the derivation of position data or other summing by counterparty is not possible. Also it has to be emphasised that, as mentioned above, removing duplicates from fully anonymised data would be impossible. In particular, full anonymisation implies also the removal of UTIs from the data because they are based on codes that identify participants. • Alternatively, records can be partially anonymised, or masked, where counterparties are given unique identifiers that are used consistently across the entire dataset.
For example, TR A could assign the identifier “1234” to Market Participant X and “5678” to Market Participant Y. Partial anonymisation could be performed by a single party, i.e., the aggregation mechanism, to perform the masking on a given dataset. In this case, if TR B assigns the identifier “ABCD” to Market Participant X, a user third party could not know it is the same entity as “1234”.
Partial anonymisation could also be performed locally in TRs, based on a set of agreed-upon and consistent anonymisation rules and translation data. Partial anonymisation allows a user to construct positions or otherwise sum up raw events by unique counterparty, without knowing the actual identity of that counterparty. This is crucial for many types of network and systemic analysis as well as for netting gross bilateral positions. While partial anonymisation is an appropriate step for providing authorities with some needed aggregated data, it remains that some mandates additionally necessarily require named aggregated data. The above approaches are possible assuming that the dataset is comprised of raw transaction event data.
If transaction flow events are summed up into positions or otherwise aggregated, it is impossible to eliminate double counting because the building blocks going into each position calculation are not known. f) User Requirements for Providing Timely Data Authorities have a need for both regular requests and ad hoc requests. Routine requests would typically come at daily, monthly or quarterly intervals (or other pre-defined regular intervals). In some cases, rapid responses to ad hoc requests will be essential, in particular under stress 16 . conditions. In general, the data should be available within a short time lag. While in some cases almost real time data is necessary, a timeliness of up to three business days (T+3), which happens to be the maximal time lag for reporting in almost all jurisdictions, would be enough for most of the mandates. Because some jurisdictions do not require real-time reporting, aggregation exercises that require data from those jurisdictions can only be done at an appropriate delay after the event. Attempting aggregation earlier would lead to incorrect results. 3.3 Further aggregation requirements The following steps would be needed for certain types of analysis but are not essential for all mandates. a) User Requirements for Calculation of Positions Several mandates require information on the positions of market participants: the sum of the open transactions for a particular product and participant at a particular point in time. This will require tools to identify the transactions to be summed.
In particular: • The participant identifiers (LEI) are required to accumulate accurate position data across TRs. The LEI with hierarchy (for consolidation purpose) is also needed for some mandates at least in a second step when the fully fledged LEI is in place. • Product identifiers (ideally UPIs, and any other instrument identifier available) are needed to do accurate product-level analysis. Different analyses require different levels of product identification granularity. • ID of underlying (e.g.
reference entity identifier, reference obligation and restructuring information in case of credit derivatives, reference entity identifier for equity derivatives, benchmark rate in the case of interest rate swaps and cross currency swaps) are required to conduct various analyses (for instance, to measure total exposure in a given reference entity, or to value the trades for any analyses where market values, rather than notional amounts, are aggregated and where the TR does not collect those market values). b) User Requirements for Calculation of Exposures The current exposure of a derivative portfolio — defined as the cost of replacing the portfolio in current market conditions net of any collateral backing it — is an important measure of risk that is of interest to authorities. Calculating exposures requires not only position data, but also data on valuations, collateral (e.g., amount and composition of applied collateral) and netting sets. Such information includes external bilateral portfolios between pairs of market participants and portfolios of centrally cleared transactions (particularly important for including collateral information).
An ID of collateral pool and netting set would be necessary to connect multiple trades to their common collateral pool and netting sets. This data will not be available in all TRs due to differences in regulatory requirements. Any aggregation solution should, however, take into account the requirements to calculate exposures where possible and to incorporate more complete data in the future.
There is also a need for authorities to be able to calculate exposures combining aggregated OTC derivatives data with data on exchange-traded products or cash instruments (bonds, equities, etc.). 17 . Box 1: Illustrations of data aggregation requirements This box illustrates the various aggregation requirements described above through some example of data uses of by authorities with particular mandates. Other uses by authorities with different mandates frequently encounter several of these issues. Business conduct supervision. The first example relates to an authority with a mandate for supervising participants with respect to business conduct (see Annex 4 for data such an authority may have access to). This regulator suspects that a bank in its jurisdiction has traded on private information obtained during a loan renegotiation with a debtor by buying credit default swaps (CDS) that offer protection against potential losses due to the default of that debtor.
Hence, the regulator wants to know the net amount of credit protection on the debtor bought by the bank over the past few days. An aggregation mechanism would allow the authority to have a broader picture in order to detect violations. As the relevant CDS transaction event records may reside in a number of different TRs, they must first be brought together. Essentially these transaction records must be extracted from their respective TRs and concatenated.
This could be done easily if each TR used the same data fields (with the same meaning/interpretation) and formats. Two particularly important data fields in this application are those containing the identities of the bank counterparty and the debtor referenced in the CDS contracts. These could be accurately searched if all TRs used the universal set of unique LEIs.
8 As transaction events may have been reported to more than one TR, the regulator would want any duplicate records to be eliminated. If all TRs applied a UTI for each of the trades that they store, this could be done simply by eliminating any records from across TRs with duplicate UTIs. Armed with a comprehensive and comparable list of duplicate-free transaction event records, the regulator could finally compute the net credit protection bought by the bank on its debtor over the past few days. It should do this by summing purchases of credit protection and subtracting any sales of credit protection.
Only ‘price-forming’ trades should be included in this calculation. 9 Calculating positions. A second example of data uses illustrates the aggregation requirement of calculating positions.
It concerns a central bank with a financial stability mandate with a need to check whether any systemically-important firms in its jurisdiction have large OTC derivatives positions. Suppose that such authority wanted to know the size of CDS positions referencing a particular country’s sovereign debt sold by Bank A (including all its subsidiaries), located in its jurisdiction. The transaction records that comprise this position potentially reside in a number of different TRs, so the authority would need the relevant trade records to be extracted and concatenated as in the first example. In this case, relevant contracts are any that end up with Bank A as the protection seller.
This includes all contracts originally sold by Bank A but which have not yet matured or otherwise terminated. It also includes any contracts that 8 In addition, if the regulator asked authorities in other jurisdictions to search for any trades conducted by legal affiliates of the bank, it would be a simple matter to find their LEIs given the LEI of the bank once the hierarchy is in place within the LEI system. 9 Non-price-forming trades, such as those arising from compression cycles and central clearing, would not affect the bank’s positions against the potential default of the debtor. They only affect the counterparties to these positions. 18 .
were reassigned from the original seller of protection to Bank A. In both of these cases, the latest information about the trade contract would be needed, so any partial terminations or notional amount increases would also have to be extracted from the TR. After harmonising data standards and removing any duplicate transaction records, again as in the first example, the position of Bank A referencing that country’s sovereign debt could finally be computed as the sum of outstanding transaction event records. Expanding this second example brings in the aggregation requirement of anonymisation. Say the authority learned that Bank A had sold a large volume of credit protection on the sovereign debt of the country mentioned above. It might then want to know the overall degree to which market participants relied on Bank A for the supply of this insurance. Simple measures of market share require a comparison of the volume of protection sold by the bank with the overall level of protection sold by all market participants.
More advanced statistical measures of network centrality take into account not only that many counterparties might rely directly on Bank A for credit protection, but that others might rely indirectly on Bank A having bought protection from a counterparty that in turn bought protection from Bank A. Computation of such measures requires data on all such links between counterparties as summarised in a matrix of bilateral positions, but the names of the protection buyers and sellers (other than Bank A) are not important. Hence, the names of these market participants could be partially anonymised before centrality is calculated. Calculating exposures.
Finally, further expanding this example illustrates the aggregation requirement of calculating exposures. Say the authority was concerned about the solvency of a financial institution in its jurisdiction and, given the centrality of Bank A as a seller of an important type of credit protection, wanted to know if Bank A was exposed to this institution through OTC derivatives. Computation of this exposure first requires data on all outstanding positions across various OTC derivative asset classes between Bank A and the institution of concern (i.e.
named data is required). As in the first example, the positions can be calculated, after data harmonisation and removing duplicates, by summing all open transaction between Bank A and the other entity. Then it requires these positions to be valued.
Some TRs will collect this valuation information, but others will not. Where it is not collected, derivatives positions may be valued using the prices of their underlying assets, which may be taken from a third-party database. This could be facilitated by the use both by TRs and third-party price providers of standard codes to identify underlying assets. In principle, any collateral posted against the market value of a bilateral derivatives portfolio should then be deducted from that market value to determine the exposure. However, not all TRs will collect this information and third-party sources of collateral data are much less readily available than for price data. 4. Chapter 4 – Legal Considerations TRs are mostly regulated at the national level by national laws, and TRs that operate on a cross-border basis may be subject to more than one regulatory regime.
10 10 The TR may be regulated in a jurisdiction other than its home jurisdiction, due to being registered, licensed or otherwise recognised or authorised in that jurisdiction, or conditionally exempt from registration requirements in that jurisdiction. 19 . Rules applicable to TRs usually concern the fields and formats for the information being reported (mandatory reporting), information being accessed (regulatory access) and organisational requirements. TRs are also usually subject to professional secrecy requirements, including relevant confidentiality/privacy/data protection laws. The feasibility of Options 1, 2 and 3 in the current legal environment depends on the compatibility of the steps needed to implement these different options with the existing rules applicable to TRs. Legal challenges in implementing the different options stem from different levels of applicable law within a jurisdiction (e.g. sectoral legislation and/or confidentiality law of general application) as well as from cross-border issues. This chapter analyses the legal considerations associated with the feasibility of the aggregation options described in Chapter 1 following three main dimensions: (i) the submission of the data to the global aggregation mechanism, (ii) access to the global aggregation mechanism, and (iii) the governance of the global aggregation mechanism.
For each component, the chapter presents legal considerations associated with the implementation of each option. The analysis focuses on the jurisdictions where TRs are established/registered/licensed 11, or will be in the short term, and pertains to the legal considerations applicable to data reported to TRs on a mandatory basis. 12 Last but not least, the analysis focuses on the feasibility of aggregating data held in TRs that are not “personal data” (i.e., data on natural persons 13). In the exceptional cases where personal data are stored in TRs, this study assumes that personal data would not be included in the aggregation mechanism because it would likely not be needed in order to satisfy authorities’ data requirements. Besides the reference material mentioned in Chapter 1, the analysis of this chapter has also been informed by the FSB fifth and sixth progress reports on the implementation of OTC derivatives reforms 14 which include descriptions of confidentiality issues related to the reporting of OTC derivatives into TRs.
The analysis also builds upon the discussion of the International Data Hub relating to global systemically important banks (G-SIBs) and the LEI global initiative. 11 Appendix D of the FSB’s sixth progress report on implementation of OTC derivatives reforms provides a list of TRs operating or expected to operate as of August 2013. The list of jurisdictions includes: Brazil, Canada, European Union, Hong Kong, India, Indonesia, Japan, Russia, Singapore and the United States. 12 There are two kinds of data reporting: mandatory reporting and voluntary reporting. The former is required by legislations and regulations, while the latter is reported without such requirements.
The ability to share data reported to TRs on a voluntary basis raises different legal issues which are out of scope of this study. 13 Personal data could be data about natural person counterparty to the trade, or data about a natural person that arranged the trade on behalf of counterparty. 14 http://www.financialstabilityboard.org/publications/r_130415.pdf http://www.financialstabilityboard.org/publications/r_130902b.pdf 20 . 4.1 Types of existing legal obstacles to submit/collect data from local trade repositories into an aggregation mechanism 4.1.1 Legal requirements applying specifically to the TR seeking to transmit data to the aggregation mechanism and regulating its capacity to share data In the existing regulatory environment, a TR seeking to transmit information to an aggregation mechanism – either to a physically centralised aggregation mechanism (Option 1) or a federated aggregation mechanism (Option 2) may face legal obstacles in its home jurisdiction, or in other jurisdictions in which the TR is regulated. In most jurisdictions legal requirements applying to TRs include limitations on the types of entities with which the TR may share data. These legal requirements may prevent local TRs from transmitting confidential information to an aggregation mechanism, depending on which entity operates the central aggregator, and which authorities have access to the aggregation mechanism. In several jurisdictions, TRs may transmit data only to national authorities, which would prevent the local TR from submitting data directly to an aggregation mechanism located outside the home jurisdiction. 15 In other jurisdictions, a local TR may share data with specified entities, or with entities of a specified kind (e.g., public entities such as authorities or regulators, and not private entities). In most jurisdictions, TRs are not permitted to disclose any confidential information to any person or entity other than authorities expressly authorised.
In some jurisdictions, the list of entities with access to TR data is defined by law 16. In others, the TRs’ supervisors may be authorised to designate the third-country entities entitled to access data held in local TRs. 17 In this context, the implementation of Option 1 and Option 2 (other than temporary local caching where necessary in the aggregation process), would require explicitly prescribing the aggregation mechanism (by law or by regulation) among the entities entitled to accessing local TR data.
This approach would require amending existing laws and/or regulation in several jurisdictions. In some jurisdictions, legal requirements include limitations on the purposes for which the local TR may share data with each type of entity. For example, some laws may restrict a local TR from sharing data with an entity that is a prudential regulator unless the data is required by the regulator for prudential supervision purposes. Unless it is possible under current law or regulation to designate or to include the aggregation mechanism as an entity entitled to access the data to the extent that the aggregation mechanism is fulfilling its mandate, TRs in such jurisdictions would not be allowed to share confidential information with the aggregation mechanism absent a change in law or regulation. Under Options 1 and 2, if the transmission of data from the individual TRs to the aggregation mechanism is performed on a routine basis, the TR may not know at the point of transmission which authorities will seek to access the data or for what purposes, and the TR therefore could 15 Brazil, India, Russia, Turkey 16 European Union 17 United States 21 .
not directly apply any access controls at its end. Where TRs are legally required to control access, they would be reliant on the aggregation mechanism to do so on their behalf. This outsourcing of controls might not be allowed in some jurisdictions without a change in law or regulation. If so, the issue would have to be addressed by the governance framework establishing the aggregation mechanism and regulating its access.
The governance issue including access rules is further discussed in Section 4.3. 4.1.2 Legal requirements of general application Privacy law, blocking statute and other laws A local TR may also be subject to legal requirements of general application such as privacy laws, data protection laws, blocking/secrecy laws and confidentiality requirements in the relevant jurisdiction, which are applicable to all the options. These legal requirements may prevent the TR from transmitting certain types of information to an aggregation mechanism under Options 1 and 2 absent a change in law or regulation. The legal requirements of general application that may prevent a TR or authority from transmitting data to the aggregation mechanism under Options 1 and 2, and may in some cases mirror obstacles that prevent participants from submitting data to a TR in the first instance. Those obstacles are discussed in the FSB’s fifth and sixth progress reports on OTC derivatives market reform implementation 18.
For example: • privacy laws may (subject to exceptions) prevent a TR from transmitting counterparty information to the central database (wherever located) where that information identifies a natural person or entity; • blocking/secrecy laws may (subject to exceptions) prevent a TR from transmitting/disclosing information relating to entities within a particular jurisdiction, to third parties outside that jurisdiction and/or foreign governments. In some jurisdictions, the TR may be able to rely on exceptions to privacy laws expressly listed in the laws or where there is a counterparty’s express written consent to the disclosure of the data. However, the requirements for consent differ across jurisdictions. In certain jurisdictions, one-time counterparty consent to disclosure to a TR is sufficient, while in others counterparty consent may be required on a per-transaction basis Consequences of breach As noted, the source of the above legal requirements may be laws, regulations or rules of the jurisdiction in which the TR is located, or of another jurisdiction in which the TR is regulated. Other sources of these requirements may be conditions of the TR’s registration, licensing or other authorisation in a particular jurisdiction, or contractual arrangements to which the TR is a party, including the TR’s own rules and procedures.
These conditions or contractual arrangements may be designed to support compliance with local laws, e.g., privacy laws. A TR that breaches these legal requirements may be exposed to civil liability or criminal sanctions in the relevant jurisdiction. Further, if a TR is required to ensure that the entity that operates the aggregation mechanism, or authorities that have access to the aggregation 18 See section 3.2.1. http://www.financialstabilityboard.org/publications/r_130415.pdf http://www.financialstabilityboard.org/publications/r_130902b.pdf. 22 and 6.3.1 of . mechanism comply with specified requirements (e.g. undertakings as to confidentiality) with respect to the data transmitted, the TR may be exposed to liability if the aggregation mechanism or authority breaches those requirements. These potential obstacles could limit the capacity of the TR to transmit confidential data to the aggregation mechanism, and could therefore limit the range of data held in the aggregation mechanism, which might prevent authorities from accessing all the information they need in carrying out their regulatory mandates. Factors mitigating the legal obstacles to transmission of data by TRs • Type of data being transferred: anonymised and aggregate-level data. The legal obstacles may differ depending on the type of data being transferred to the aggregation mechanism under Options 1 and 2. Sending aggregate-level data or data in anonymised 19 form could mitigate most of the confidentiality issues identified above which apply to the transmission of confidential data. On the other hand, it should be noted that transmission of data that has already been anonymised (e.g., with no LEI or other partyrelated information) or that has already been summed faces serious drawbacks, such as the inability to eliminate double-counting and the inability to perform calculations of positions or exposures as discussed in Chapter 3. • Authorities acting as intermediaries for the transmission of data into the database. Transmitting data from local TRs to the aggregation mechanism via authorities may alleviate some of the legal concerns identified above, since most authorities have, unlike TRs, the capacity to share confidential information with other authorities, provided certain conditions are fulfilled, notably within existing frameworks of cooperation arrangements for data sharing. 4.2 Legal challenges to access to TR data In a few jurisdictions, direct access by foreign authorities to data held in local TRs is not permitted.
However, in some jurisdictions 20, foreign authorities may be granted indirect access to the data via national authorities – usually the supervisor of the local TR (or after approval of the supervisor) – provided MoUs have been concluded. In most jurisdictions, regulatory access to TR data is provided by law and includes access by third country authorities, provided certain conditions are met. These conditions may include the conclusion of MoUs - or specific types of international agreements 21 - between relevant authorities on data sharing. 19 A methodology to do so would need to be further defined and demonstrated. Different types of anonymisation are described in Chapter 3.
The methodology would need to address the issue that, in some circumstances, anonymised counterparty identities may be ascertainable e.g. based on historical trading patterns or account profiles, or because of lack of depth in the market. 20 Brazil, Russia, and Turkey 21 For example, in the EU, as a condition for direct access to EU-regulated TR data by third country authorities from jurisdictions where TRs are established, the European Market Infrastructure Regulation (EMIR) requires that international agreements and co-operation arrangements that meet the requirements of EMIR be in place between the third country and the EU. For third country authorities from jurisdictions where no TR is established, EMIR requires the conclusion of cooperation arrangements. 23 .
In some jurisdictions, pre-conditions to access by certain authorities have to be met. For example, a TR may be required to take specified steps before sharing information with an entity, such as ensuring that an agreement or undertaking as to confidentiality, or indemnification 22 in respect of potential litigation, is in place with the requesting entity. Under Options 1 and 2, authorities would access global OTC derivatives data via the aggregation mechanism. New rules specifying who may access the data, the coverage of the information that may be accessed, and the conditions for access would therefore need to be globally agreed as developed in the governance section below. These rules and conditions for access would need to reflect any legal conditions under which the data was transmitted to the aggregation mechanism.
This new international framework may solve the existing access issues above to some extent in a sense that this framework can be a substitute for bilateral MoUs. 23 Under Option 3, authorities would access information directly at local TRs. Option 3 would depend on the completion of the additional steps required under the existing regulatory frameworks to permit access to local TRs by worldwide authorities or would require changes in the existing regulatory frameworks. 4.3 Legal considerations for the governance of the system 4.3.1 General analysis The objective of this section is to analyse the legal considerations related to the governance of the aggregation mechanism for each option proposed, analysing what would likely need to be defined and agreed internationally to ensure the global aggregation mechanism could be implemented and managed. Under Option 1, a physically centralised aggregation mechanism would be established to collect and store data from local TRs.
This aggregation mechanism would subsequently aggregate the information and provide it to relevant authorities as needed. Some changes to the existing regulatory frameworks would be required to set up an aggregation mechanism entitled to collect confidential information stored in local TRs. Option 2 would not physically collect or store data from TRs in advance of a data request, instead it would rely on a central logical catalogue/index to identify the location of data resident in the TRs. In this model, the underlying data would remain in local TR databases and be aggregated via logical centralisation by the aggregation mechanism, being retrieved on an “as needed” basis at the time the aggregation program is run. Options 1 and 2 require a global framework to be defined specifying (i) which entity would operate the aggregation mechanism, (ii) how the aggregation mechanism would be managed and overseen/supervised, (iii) access rules (which authorities would have access to which information according to their mandate and confidentiality restrictions in the use of data). 22 For example, in the US, the Dodd-Frank Act requires that, as a condition for obtaining data directly from a TR, domestic and foreign authorities agree in writing to indemnify a US-registered TR, and the SEC and CFTC, as applicable, for any expenses arising from litigation relating to the data provided.
The CFTC issued a final interpretive statement and the SEC issued proposed exceptive relief. 23 Other legal issues, e.g. indemnification issues, would still need to be solved. 24 . The framework for Option 1 would further require specifying the location of the physically centralised aggregation mechanism and the information to be collected and stored there. The framework for Option 2 would further require agreeing (i) which information would be incorporated into central logical catalogue/index for logical centralisation and access, (ii) how the federated aggregation mechanism would be operated. Option 3 would not require setting a global governance system but require the conclusion of international agreements (cooperation arrangements, memorandum of understanding, etc.) between relevant authorities and resolution of indemnification issues as mentioned in the previous sections. 4.3.2 The need for global governance frameworks under Options 1 and 2 Assuming an international commitment to set up an aggregation mechanism for OTC derivatives data, different possible governance approaches would permit the implementation of such a mechanism. Considerations for defining the supervisory/oversight framework entity running the database and the global Under Options 1 and 2, the global framework would likely need to define which entity operates the aggregation mechanism and in particular the nature of the entity that may run and manage the aggregation mechanism and how this entity could be supervised/overseen (if a private entity) or otherwise governed (if a purely public entity). At least two cases can be envisaged, depending on whether the database is run via a public-private partnership (cf. model of the LEI initiative) or if the central database is operated by a public entity (cf. model of the Data Hub). • Public-private partnership In the current landscape of TR services providers, the same global companies operate local TRs established in various jurisdictions, offering TRs services in line with each jurisdiction’s local requirements.
The existence of companies running different local TRs could pave the way to building a global infrastructure that would aggregate the information contained in local TRs on a not-for-profit basis and subject to public sector governance. In that regard, the LEI initiative provides an insightful example comprising a public-private initiative, leveraging the knowledge and experience of local infrastructures, with a global regulatory governance protecting public interest and open to all authorities worldwide. Several models could already be envisaged for the supervision/oversight of an aggregation mechanism on OTC derivatives data operated by a private entity. The private entity running the aggregation mechanism could be supervised/overseen by a college of authorities from different jurisdictions, which would set up a global supervision/oversight framework.
Another framework would rely on the direct supervision/oversight of the private entity by an international institution under a global governance framework. The global governance framework of the LEI initiative (which was set up in two years from the G20 mandate to the first operationalisation) is an example to consider, although aggregation of TR data is a more complex task than the generation of an LEI code. The key elements from the LEI initiative, which could be helpful in designing a global framework 25 . governing a TR data aggregation mechanism if run by a private entity, are summarised in Box 2. Box 2: Global LEI initiative G20 mandate to FSB (Cannes Summit, November 2011) The LEI initiative includes a four tiered system with a governing charter for the Regulatory Oversight Committee (ROC) 24, a Global LEI Foundation (GLEIF) as well as operation units such as the Central Operating Unit as well as the federated local operating units. 25 The LEI identification standard is provided by the International Organisation for standardisation (ISO) or more specifically ISO 17442, designed to ensure the unambiguous identification of the counterparties engaging in financial transactions. In this framework the ROC will take ultimate responsibility for ensuring the oversight of the Global LEI system, standards and policies. - ROC, established by Charter set out by the G20 and FSB. Members are authorities from across the world.
Responsibility for governance and oversight of the Global LEI system, and delivery of the broad public interest. The following are eligible to be a Member of the ROC: (1) any public sector authority and jurisdiction including regulatory and supervisory authorities and central banks; (2) public international financial institutions; and (3) international public sector standard setting, regulatory, supervisory, and central bank bodies and supranational authorities. - GLEIF, governed by independent Board of Directors (composed with balance between technical skills, sectoral experience, geographic balance). Upholds centrally agreed standards under a federated operating model. Will be established as a not-for-profit foundation in Switzerland.
Will operate central operating unit. FSB acts as a Founder of the foundation. - Local Operating Units. Build on local knowledge, expertise, and existing infrastructures. Operate to centrally agreed standards under the federated operating model. The FSB report, “A Global Legal Entity Identifier for Financial Markets”, highlights the creation, governance and function of a global LEI system. • Public entity An aggregation mechanism could also be run by a public entity.
Given the nature of the data that is collected based on mandatory reporting requirements, establishment of public entity might be less complicated from a legal perspective. The Data Hub on global systemically important banks (described in Box 3 below) has been recently established by the BIS through the conclusion of a Multilateral Memorandum of Understanding. The legal framework applicable to the Data Hub is a useful starting point for considering the implementation of Options 1 and 2, in the sense that the hub centrally collects global financial 24 http://www.leiroc.org/publications/gls/roc_20121105.pdf 25 See FSB report - http://www.financialstabilityboard.org/publications/r_120608.pdf 26 . data, including confidential data, and is able to share this information with relevant authorities. A similar governance framework could be envisaged for an aggregation mechanism comprising a public entity operating the infrastructure and the establishment of an international Governance Group. While the Data Hub is designed to be a connector among regulators, the aggregation mechanism being discussed in this report could be directly connected to TRs, albeit under regulatory oversight. Box 3: The International Data Hub As part of wider G20 initiatives to improve data to support financial stability, the FSB has developed an international framework that supports improved collection and sharing of information on linkages between global systemically important financial institutions and their exposures to sectors and national markets 26. The objective is to provide authorities with a clearer view of global financial networks and assist them in their supervisory and macro-prudential responsibilities. The key components of the governance of this initiative are the following: - Harmonised collection of data: common data templates for global systemically important banks have been developed under the FSB leadership to ensure consistency in the information collected. - Central hub: The International Data Hub has been set up 27 and centrally holds the data collected.
The data hub is hosted by the Bank for International Settlements (BIS). A multilateral memorandum of understanding (Multilateral Framework) establishes the arrangements for the collection and sharing of information through the Hub. Currently, the Framework is signed by banking supervisory authorities and central banks from ten jurisdictions.
Access of these jurisdictions to confidential information is contingent on the reciprocal provision and restricted to specific purposes such as supervisory activities. - GSIBs data is collected by their respective home authorities (data providers) and then passed on to the Data Hub. Data providers use their best efforts to ensure the quality of the data transmitted to the Hub. The Data Hub prepares and distributes standard reports to participating authorities (data receivers) on a regular basis.
In addition, data receivers can require additional information from the Hub, which fulfils the request after obtaining written consent from data providers. - Hub Governance Group: Participating authorities established a Hub Governance Group (HGG) to oversee the pooling and sharing of information. The HGG is responsible for all governance aspects of the multilateral arrangement. Considerations for the submission of data to the aggregation mechanism and addressing confidentiality issues The global governance framework would likely need to define how the aggregation mechanism collects data from local TRs. Two cases could be envisaged at this stage. 26 See recommendations 8 and 9 of the Report to the G20 Finance Ministers and Governors on “The Financial Crisis and Information Gaps” from November 2009, available at http://www.financialstabilityboard.org/publications/r_091029.pdf. 27 The Hub operations started in March 2013 with the collection of weekly data on the G-SIBs’ 50 largest exposures and quarterly data on aggregated claims to sectors and countries. 27 .
Firstly, the aggregation mechanism framework could be built on a global agreement mandating local TRs to submit relevant data (to be agreed on, which might or might not include confidential information) to the aggregation mechanism – and, where needed, changes to regulatory frameworks enabling the implementation of mandatory reporting to an aggregation mechanism. Requiring by law for the local TRs to report to the aggregation mechanism with the conclusion of a Multilateral Memorandum of Understanding for cooperation among relevant authorities would address, in most jurisdictions, the confidentiality obstacles identified above. This would however require a change in law in most jurisdictions. Secondly, the aggregation mechanism framework could be built with information flowing via national authorities. This is the approach followed for the Data Hub: national authorities transmit data (including confidential information) on G-SIBs to the central hub, which is entitled to centrally hold and share confidential information with relevant authorities participating in the framework.
28 As for the Data Hub, the protection of confidential data would have to be addressed via the conclusion of Multilateral Memorandum of Understanding. Strict confidentiality rules applying to the aggregation mechanism may also need to be defined. Laws applicable and confidentiality requirements in the jurisdiction where the aggregation mechanism resides and where data are stored either permanently under Option 1 or temporarily under Option 2 will be key components of the framework. 4.3.3 Considerations on access rules Under Options 1 and 2, authorities would access global OTC derivatives data directly at the aggregation mechanism. The global governance framework would therefore need to define rules on access to the information held at the central aggregation mechanism.
These rules may need to specify: • Who may access the aggregation mechanism (list of relevant authorities, official international financial institutions 29, etc.). • Scope of data access: The aggregation mechanism would provide authorities with a level of access in line with the principles defined in the Access Report. • Permitted use of data: the permitted uses for financial stability purposes and other relevant mandates would need to be defined, as would protection of confidential information that is accessed and consequences of any breach. • Modalities of access (direct vs indirect access, standard vs ad hoc requests). Under Option 3, individual authorities directly collect the raw data they need from local TR databases and then aggregate the information themselves within their own systems. This option can be implemented in the existing legal frameworks, if each relevant individual authority has access to the information it needs in all relevant local TR databases. 28 However, given the volume of data at stake for OTC derivatives, an automated process enabling national authorities to forward the relevant data to the database would be required. 29 In the Access Report, the IMF, the World Bank and the BIS are stated as official IFIs that foster and support financial stability through general macro assessments of global OTC derivatives markets, sectors or specific countries. 28 . The implementation of this option would therefore require solving the existing legal obstacles relevant to access to data (described in the previous section) in order to ensure that the legal frameworks applicable to local TRs in each jurisdiction allows access to TR data by third country relevant authorities: • granting access to third country authorities in the few jurisdictions where foreign authorities are not entitled to access TR data, • addressing the indemnification issues in jurisdictions where access to TRs data by foreign authorities is conditional to the conclusion of indemnity clauses, • concluding the necessary Memorandum of Understanding or other type of international agreements. It should be noted that, under Option 3, TRs as gatekeeper may interpret conservatively the minimum requirements for access set in the Access Report. This could lead to arbitrary decisions regarding the evaluation of mandates as well as what kind of data should be shared for each mandate. 5. Chapter 5 – Data & Technology Considerations As the implementation of data reporting to TRs gathers momentum, the development of technical and data solutions for data collection and aggregation has been largely at the local level. With local implementation advancing, it has become clear that different jurisdictions have implemented different solutions in the areas of technology choices or data standards and formats due to a number of factors: (i) local practices of infrastructures or market participants; (ii) jurisdictional-specific regulatory regimes; or (iii) the physical distribution of data over many different geographical locations which is in itself a significant factor, regardless of the progress made on standards, formats and other data and technology practices. In addition, there are potential data duplication issues resulting from counterparties reporting to multiple jurisdictions and TRs because of a combination of regulatory and other reasons. This chapter discusses the data and technology considerations associated with meeting authorities’ requirements for aggregated data under different choices of model. • to avoid the double-counting of transactions through the aggregation process.
This strengthens the case for the introduction of a global standard for identifying transactions uniquely. Lastly, this chapter reviews core technology considerations for availability and business continuity. 5.1 The Impact of the Aggregation Option on Data and Technology The requirements for data standards and the specification of technology to support aggregation do not drive the choice of aggregation model. The development of global standards for derivatives data and their aggregation is a foundational requirement under any data aggregation model. Standards form the basis for the interoperability of derivatives data; they are agnostic to choice of aggregation option as they are a prerequisite for every option. 29 . Indeed, the choice of aggregation option drives some key technological requirements. In this respect, it may be useful to think of the three options in terms of a nested set of technology requirements – there are some requirements that all three Options have, some requirements that Options 1 and 2 have but not Option 3, and some requirements that Option 1 has but not Options 2 and 3. In particular: • All three Options require a clear definition of the data so that there is unambiguous shared meaning among all parties, involving common data standards and understanding of business rules, so as to allow the collection of data for aggregation purposes. • In addition to these data standards requirements, both Option 1 and Options 2 require a shared catalogue to identify where data resides. • In addition to these data standards and cataloguing requirements, Option 1 adds a requirement for storage of data collected from TRs on behalf of the authorities. Because many of the data and technology factors apply independently of the final selection of aggregation option, this chapter addresses these factors more generally in terms of best practices in data and technology management. 5.2 Data aggregation and reporting framework In any data reporting or aggregations framework, data is accessed through a request (ad hoc or pre-defined) submitted to the system. The system performs the following functions: • verifies the identity and access rights of the data requestor; • analyses the request according to the data scheme, syntax and semantics; • controls its consistency and integrity; • optimises it for the purpose of execution; • executes the request according to storage scheme and access methods; • provides the results to the requester; • checks the performance of the aggregation mechanism and network performance (e.g.
response times, latency, traffic bursts). In the case of data aggregation framework of TR-based data access, the complexity of servicing a request for execution increases since the data might be stored in different physical locations, subject to different access rights, subject to different data standards and technology solutions, with possibly different access right methods and storage schemes. Regardless of the chosen system of data aggregation and regardless of its physical implementation, the general form of a request has to be defined as well as the protocol for analysing and interpreting it to allow meaningless aggregation of the data. 5.3 Data reporting In many jurisdictions reporting requirements oblige TRs to provide a specific set of data elements to regulators. At the time of this report, not all regulators and legislators have provided specific instructions as to the format and content of those the data elements they 30 . request but have rather left it at the economic definition level, leaving it to the discretion of the TRs to define those fields from a technical point of view. These differences and the absence of in standards and formats used have added complexity to the aggregation process at the jurisdiction and global levels. 5.4 Principles of data management to facilitate proper data aggregation Effective data management is a critical component of any data collection, reporting and aggregation framework. Accurate and useful data aggregation requires sound data management principles, including the following: • Regarding the underlying data: o o Standardisation, o • Integrity Availability and traceability. Regarding the technological arrangements: o Scalability, o Flexibility, o Business continuity, o Security. To evaluate the design and implementation methods of the OTC derivatives data aggregation approaches, each principle is described below. Technical implementation and best practices around each principle can vary depending on the aggregation approach. 5.5 Principles of data management regarding the underlying data 5.5.1 Data Integrity From the perspective of the data aggregation of trade reports, data integrity can be defined as ensuring that the processing involved in the aggregation: • Does not distort or misrepresent the data that was originally reported. • The result of the aggregation properly represents the underlying data without adding to or subtracting from them. Without integrity results could be inaccurate and inconsistent, thus creating questions about its authenticity and removing the ability of authorities to compare data from different sources or over time.
The concept of integrity also depends on the chosen aggregation model: under Option 1, the aggregation mechanism shall be designed so as to store and manage its data properly, while under the other options model integrity would mainly apply to consistent communication between entities. The principle of integrity must therefore remain flexible and be adapted to each particular model. 31 . Data quality Data integrity and data quality are related concepts. Data quality is the fitness of the data for its intended purpose. The single most important factor contributing to improved data quality is the adoption of standards that uniquely define and describe the data elements that comprise the components of financial instruments and transactions. Conformance to standards by market participants, TRs and authorities improves their ability to identify and remediate errors and discrepancies throughout the data supply chain. The discussion on data quality applies to all the aggregation models considered, with varying degrees of responsibility resting with the TRs, the aggregation mechanism and the individual authority. The following dimensions of data quality apply from individual data elements in a trade report to highly aggregated summaries of transactions and positions and should be considered in the analysis of the data aggregation approaches: • Completeness Missing or otherwise incomplete data for derivative products can render all other data about the products meaningless.
To ensure completeness of data for aggregation, the surest and most efficient way would have been for all TRs to collect and populate the same set of data elements. However, since such a unique TR data specification is not currently envisaged at an international level, a second best consists of ensuring that the data can be translated into a consistent standard. This still entails, though, significant constraints regarding specifications of the data stored by TRs. • Accuracy The values for a data element must conform to a standard definition and meaning to be accurate.
Likewise, the data elements collected by each TR should have unambiguous shared meaning and conform to standards for their content values in order for data aggregated across TRs to be accurate. Deviations from a standard definition and meaning for a data element might result in the uneven acceptance of valid values across TRs, degrading the quality of the data. However, when these deviations are small and the population is large, the data may still be considered ‘fit for purpose’ and may yield acceptable results when aggregated. • Timeliness In order to be timely, data must be available when and where needed, and provide the most current content.
However, aggregation across TRs is challenged by the collection mandates and reporting calendars of global authorities. This includes any differences in the requirements for the frequency and location of data access by authorities and the frequency and location for data collection from market participants. Since OTC derivatives contracts are often active over long periods of time the standards for maintaining and refreshing data have to be determined and harmonised across TRs and jurisdictions. Depending on the chosen scenario, the responsibility for updating data should be clarified, whether relying on TRs or on the global aggregation mechanism since this could hinder consistent aggregation. 32 .
• Consistency Data must have unambiguous shared meaning, allowable values, and business rules for their creation, maintenance, and retirement among the TRs. Without consistency, the quality of data across TRs will vary and negatively affect the ability to rely on the results of aggregation of transactions and positions. The agreement and setting of standards for TR data is a necessary condition to achieve consistency. • Accessibility To be accessible, collected data must be available to authorities where and when needed. Accessibility for aggregation is dependent on both technology capability and the legal agreement that grants authorities access to the data. Technology capability includes the data security systems and controls that govern permission to access data and the agreement among authorities on the TR governance process. • Duplication This dimension, often referred to as ‘Uniqueness’, is critically important to the prevention of double-counting of transactions and positions across TRs.
The development of standards for unique entity, instrument, and transaction identifiers provides the foundation for the prevention of duplication. As described in Chapter 3, avoidance of duplication is necessary for the purpose of aggregation. Standards for data content are in turn necessary to provide the capability to identify, correct, and prevent data duplication both within and among TRs. Operational factors contributing to high quality TR data Data quality must be addressed from that moment the data arrive at the TR and at every point where data are exchanged.
Both technical and business data quality practices must be applied to ensure the interoperability of the data among market participants, TRs, and authorities. The following operational aspects of data quality may need to be considered to facilitate proper data aggregation: • Whether the data are technically capable of being processed by the receiver and contain meaningful values. • Whether validation can be performed on the data to ensure consistency and completeness, and to avoid duplication. • Whether there are further checks for accuracy that could or should be carried out seeking to ensure that the reported items are correct. • Whether data quality is being managed proactively or reactively. • Whether and what combination of technical and business data quality checks are undertaken. While individual TRs will carry out validation of the data that is reported to them it is important that various TRs operationalise data quality processes in a consistent way 30. Thus the discussion here is about the data quality issues that are pertinent to integration of data 30 It is assumed that ensuring that the reports submitted to the trade repositories meet quality standards is outside the scope of any central aggregation solution. This role will be performed variously by the trade repositories themselves and the supervisors of the trade repositories and reporting entities according to the rules prevailing in a specific jurisdiction. 33 .
from several TRs for aggregation rather than data quality from the point of view of a single TR. A variety of technical checks would need to be conducted including checks for conformance to standards, format, allowable values, and internal consistency. Such checks would require some sort of a data dictionary and validation rules that define the allowable formats and values of the individual items or groups of items. This implies that an agreed-upon set of definitions and meanings of the data by industry participants, TRs, and authorities is essential, regardless of the aggregation mechanism. Some of these checks would also require access to reference data, such as those for counterparty and product identifiers as well as elements like country and state codes, including having a robust reference data management function. 5.5.2 Data standardisation Data standardisation is a necessary tool for effective high quality aggregation under each OTC derivatives data aggregation approach, although methods to achieve it may vary according to the particular approach.
It would be critical to determine which of the data being reported to TRs needs to be collected, reported and stored in a sufficiently consistent and standardised form so that the data can be easily and accurately aggregated for the regulatory purposes described elsewhere in this report for either aggregation model 31. Data standardisation also must address the potential need in some cases for authorities in their financial stability analysis to combine and aggregate OTC derivatives data with other data, such as data gathered from other sources, on other trades (e.g. exchange-traded derivatives, or cash market trades), and reference data, particularly defining the products traded and identifiers for their underlying instruments or entities. There are different approaches to standardisation which may achieve different levels of consistency. Achieving standardisation The most straightforward method for achieving standardisation is to implement consistent international standards for reporting of data to TRs and/or from TRs to authorities. Ahead of formal international standardisation, the public and private sectors can work together to agree on a common approach to be used as widely as possible.
In some jurisdictions, it might be possible to mandate the use of such an approach even if it is not an international standard. 32 The risk that different jurisdictions might endorse incompatible approaches makes it is highly desirable that the various authorities attempt to coordinate their approaches so that the necessary standardisation is achieved for the data aggregation mechanism. Such coordination would be valuable to all the aggregation models under consideration.
Alternatively, national authorities could identify common data requirements, and task TRs to cooperate internationally to identify a data standardisation approach that would be workable across TRs in achieving these requirements. 31 It is not intended to suggest that this means that the other reported data can be of lower quality, only that these are the key items necessary to make aggregation work. 32 For example, EU Regulation 1247/2012 allows for ESMA to endorse a standard product identifier to be used for EMIR trade reports. 34 . Standardisation can arise at two different points in the “data supply chain” and different aggregation approaches put emphasis on different points. • Upstream of each TR by elaborating common standards for reporting to TRs in the first place, • Downstream from TRs by using a translation mechanism to aggregate and share data originally provided in different formats. The translation could be carried out by the TRs before onwards transmission of the data, using a common TR data standard, or later in the processing. Note that “downstream aggregation” is complementary to “upstream aggregation” and that both might be necessary. Key OTC derivatives data elements requiring standardisation The following data elements have been identified in the Data Report as key to the aggregation process. • Counterparty identifier • Product identifier / product identification taxonomy • Transaction/trade identifier These are discussed in more detail below. Other data elements that have been identified as necessary or desirable to aggregate the data are: 33 • Identifier of the underlying of the derivative (cash market), • Timestamps of the execution, confirmation, settlement or clearing of a contract, • Types of master agreements. Counterparty identifier The counterparties to derivative transactions could be both legal persons and natural persons. The need for standardisation primarily applies to de jure and de facto legal persons. This report does not propose requiring standardisation of the identifiers for natural persons where alternative solutions will be employed. OTC derivatives data standardisation for legal persons needs to rely as much as possible on the LEI (see Box 2 in Chapter 4). Product identifier/ product identification system An international product classification system for OTC derivatives would provide a common basis for describing products, as described in the Data Report. Without a shared taxonomy the aggregation of data might be impossible or at best extremely difficult.
A standardised way of identifying the product traded will enable both the identification of situations where reports relating to the same product are made to multiple TRs, the identification of pockets of risk 33 This report assumes that data elements such as country codes and currency codes for which there are existing international standards that are well-used in other areas will also be used for the data under consideration here and so they are not discussed further. However, an affirmative use of these standards by the authorities in their guidance to the TRs could be very helpful. 35 . particularly in the areas of credit products and related instruments, and also enable comparisons of trading on related, but not identical, products. However, the standardisation of the depiction of financial products/instruments/contracts across markets and geographies has lagged behind the development of counterparty identifiers (i.e. the LEI). The requirements for product identification in order to achieve the objectives of data aggregation are: • An identifier that is sufficiently precise for the purposes of the authorities using the data, although recognizing that it may need to be supplemented by other data on the report. • An identifier that either explicitly or implicitly (through reference data) includes a well-articulated and precise classification hierarchy, so that data aggregation / analyses that does not require precise detail of the traded product are possible. • An identifier that is open-source, available to all users and has open redistribution rights. • A governance process for adding new values to the identification system, recognizing that new products will come into being over time. Authorities should have some role in the governance process. • An identifier that incorporates an approach that allows for historic data comparisons in a straightforward way, e.g. by not deleting or mapping old values.
The approach would maintain a version history of the identifiers. Several approaches have been put forward in the area of OTC derivatives product classification. These include approaches based on existing international standards (e.g. CFI Codes – ISO 10962 and ISO 20022 financial data standard) and industry-developed approaches (e.g.
from ISDA, the Financial Industry Business Ontology, algorithmic contract type unified standards). For the purposes of aggregation, either all jurisdictions should select the same approach or, if this cannot be achieved, then it should be possible to translate the approaches used at the reporting level into a common approach for integration, i.e. any integration process is likely to have to need a common approach even if the underlying reporting allows for more variation. Transaction/trade identification OTC derivative transactions may be reported to many different TRs and can, over their life, experience multiple amendments, notations and risk-mitigating exercises. If there is no standardisation, but instead different jurisdictions or different TRs use their own approaches, there could be problems in the areas of: (i) double counting if transactions are reported to different TRs; (ii) linking transactions when a life cycle event occurs and different events are reported to different TRs; and, (iii) difficulty in linking an original bilateral transaction to the resulting cleared transactions. Attempts to match up reports using other fields without some version of the UTI concept (such as the participants involved or the time of trade) are relatively complex and likely to be inefficient and inaccurate. 36 . Like the product identifier, the standardisation of transaction identifiers across markets and geographies has lagged behind the development of the LEI. While some jurisdictions have implemented authority-specific transaction identifiers, there is no global standard in place at the time of this report. There are also some jurisdictions that have no authority-specific transaction identifier. Data harmonisation In the absence of full data standardisation, reported data would need to be harmonised in order to ensure comparability. Harmonisation can bear different meanings depending on the chosen aggregation mechanism and the envisaged use of aggregated data.
Harmonisation is understood here as the process of adjusting differences and inconsistencies among different systems, methods or specifications in order to make the data derived from those systems mutually compatible. Harmonisation is required for fields where no standardisation has been agreed on. There are some proposals to develop a translation mechanism that will permit the aggregation of data originally provided in different formats. However, such a translation is not just a matter of format since the content of the data fields might also require translation.
Standardisation arrangements such as those discussed above apply to only certain key data elements. Harmonisation of fields would be critical under any option to achieve useful aggregation. While many vendors and technologists propose their own translation mechanisms or tools to aggregate data in disparate data stores and formats, such aggregation is prone to significant margins of error. While it might be helpful to provide initial leads for surveillance or enforcement activities such a technology is not a good substitute for standardisation of data to report the same data elements across the globe. Where complex datasets such as those dealing with OTC derivatives data are concerned, such methods could have higher rates of failure.
In addition, many of these also require investments to develop data dictionaries and intermediate translation standards in order to work. So, the costs of standardising data at the source may be well worth bearing, when set against the long-term benefits for decades to come. 5.5.3 Availability and traceability Data must be present and ready for immediate use and aggregation. There is an operational risk that the data will not be present and ready for use when needed for aggregation.
Market participants must deliver the data to TRs in time to allow the TRs to complete their processing cycle with final delivery or availability to authorities. Local and global authorities have different deadlines for reporting, holiday calendars, and operating hours. In the global context, there is no “end of day” for TRs, only specified times on a 24-hour clock by which data must be available to each authority served. In the case of Option 1, the availability of data at report/ aggregation time becomes the responsibility of the aggregation mechanism, even though in the longer run data also has to be available at the TRs.
Under Option 2, both the aggregation mechanism and the TRs have to be responsible for availability since both the catalogue/ index and the source data would be necessary to achieve desired results. Under Option 3, most of the responsibility for availability rests with the TRs. The ability to track the history of changes to content and location of data from their inception to disposal is the primary characteristic of traceability. When collecting data for the purposes 37 .
of aggregation, data quality is enhanced when the origin of data, the reasons for any changes, and those responsible for any changes to the data are known. While the primary responsibility for most of the changes to the data rests with the TRs, in case the aggregation mechanism makes changes to data such as anonymisation or masking, maintaining that audit trail would be the responsibility of the aggregation mechanism. 5.6 Principles of data management regarding the technological arrangements Solid technological underpinnings are critical for TRs to operate effectively in a secure, reliable, scalable and flexible manner to perform their functions effectively. The same considerations apply to data aggregation of TR data, albeit in a modified manner. To be able to evaluate each aggregation model, the principles of data management regarding the technological arrangement are discussed below. To be effective, a data collection, reporting and aggregation mechanism requires a technology environment that addresses the following: • Scalability, • Flexibility, • Business continuity, • Security. 5.6.1 Scalability Scalability is the ability of a system to continue operating at a required level of performance as the size or volume of data processed increases.
The system must be able to provide the same level of response time to queries whether the aggregation is for a single TR or across multiple TRs. As jurisdictions and TRs join in the global collection of derivatives data, the system must be able to grow to accommodate the increased volume of data collected, queries submitted, and reporting required. Beyond the collection and distribution of data, aggregation requires the raw processing power to perform calculations, respond to queries, and generate the reporting that is the reason for collecting the data. Under Options 1 and 2, the system must be able to service large numbers of simultaneous users on a global 365x24x7 basis.
Specifically under Option 1, there is a greater burden on securely receiving and storing large amounts of data. Under Option 2, and to some extent under Option 3, there is a greater burden on communications, multilateral data exchange, and the ability to locate data resident in distributed databases. 5.6.2 Flexibility Flexibility is the ability of a system to adapt to changes in requirements or processing demands. Aggregation requirements will vary based on the regulatory or supervisory mandates of the users of the system.
The system must be able to adapt to the diversity of requests and rapid evolution in queries as users become more sophisticated in their understanding of system capabilities and the data available. The system also requires the ability to adapt to new instruments, transactions, and the data storage they require. 38 . With experience, end-users will look at aggregation in different ways, with more complex queries, and demands for greater access to data. Flexibility impacts both Options 1 and 2 similarly, given that the aggregation mechanism has the responsibility to service the end-user regardless of the location of the source data. 5.6.3 Business continuity Business Continuity is “the capability of the organisation to continue delivery of products or services at acceptable predefined levels following a disruptive incident”. Business Continuity Management (BCM) is “the holistic management process that identifies potential threats to an organisation and the impacts to business operations those threats, if realised, might cause, and which provides a framework for building organisational resilience with the capability of an effective response that safeguards the interests of its key stakeholders, reputation, brand and value-creating activities.” 34 BCM needs to look beyond IT technical recovery capability and into a more comprehensive recovery of the business considering: (i) reputational risk; (ii) data supply chain (including TRs, connectivity, etc.); (iii) communications; (iv) sites and facilities; (v) people; (vi) finance; and (vii) end-users. The above should be considered against the changes to the environment in which the aggregation mechanism operates including political, economic, technological, social, legal, security, natural disasters, etc., taking into account crises and incidents that might disrupt the aggregation mechanism’s ability to deliver the services. The aggregation mechanism needs to exhibit network stability.
It should plan for both short-term service interruptions (generally caused by technical issues) and severe service interruptions (generally caused by larger events outside the control of the aggregation mechanism and jurisdictions). The latter might require the activation of an alternative site. Option 1 offers the possibility to manage the continuity of service in a single location, but emergency procedures (e.g. disaster recovery) need to be implemented in order to avoid single points of failure. Option 2 requires TRs to be always appropriately available in order to ensure required access. The case of unavailability of data in a single TR may produce inconsistencies and hamper the possibility of receiving complete information leading to incomplete or incorrect results. 5.6.4 Data security Data security is a comprehensive approach that includes the following: • Availability / Accessibility - information is available and usable when required, and the systems that provide it can appropriately resist attacks and recover from or prevent failures; • Confidentiality - information is observed by or disclosed to only those who have a right to know; • Integrity - information is complete, accurate and protected against unauthorised modification; 34 Source ISO22301:2012. 39 .
• Authenticity and non-repudiation - data source can be trusted. Achieving data security requires alignment of IT security with business security. Global TR data aggregation necessitates the development of a security policy for the ‘end-to-end’ environment, which incorporates the control of the use of the data at the TR and at the aggregation mechanism. Data security within the ‘end-to-end’ environment needs to consider technical security as well as environmental security. It is also important for the aggregation mechanism to be able to have preventive practices with respect to security incidents (cyber-attacks, computer crime etc.). Under Option 1, high-reliability tools and procedures for managing centralised access to the data would need to be developed. Moreover, as all the data itself is housed in the aggregation mechanism, it needs to be stored in a secure location.
This model poses a risk in having to implement a powerful security system to ensure the confidentiality of data stored in the central hub and the ability to centralise security checks on the stored data. Under Option 2, data security would need to ensure secure access by the central index to the databases of different TRs and protect the confidentiality of local caches, which could include subsets of actual TR data. In these cases it will be also be necessary to establish secure and reliable network protocols. In the case of direct access from authorities to TRs, bilateral agreements and technical solutions need to be put in place.
The aggregation mechanism has to have a governance function, which would manage and implement the data access rights of different regulators. The governance component itself would need to have a clear audit trail of its own actions as well as need to manage a strong framework of accountability to the regulators. The governance component would need to conduct internal audits to ensure adherence to its operating practices and principles. 6. Chapter 6 – Assessment of Data Aggregation Options This chapter provides an assessment of the pros and cons of each option with respect to criteria and principles discussed in Chapters 3, 4 and 5.
[to be completed after public consultation] Criteria of Assessment On the basis of the analysis presented in Chapters 3, 4 and 5, a list of criteria to assess the different options has been derived from the perspective of uses, legal, data and technology aspects. This list consists of a set of key aspects and requirements for the aggregation mechanism: Uses • Scope of data needed: as recalled in Chapters 1 and 3, to fulfil their mandates, authorities require access to aggregated data at different levels of depth, breadth and identity. The ability of the aggregation mechanism to meet the scope of data needed by authorities in terms of level, breadth and identity will be analysed. • Use flexibility: as noted in Chapter 3, most authorities’ mandates require various forms of aggregated data (e.g.
transaction-level data, or summed by counterparty, 40 . sector, currency, trade venue, date, product, etc.). The complex set of needs of various authorities’ calls for an aggregation mechanism providing flexibility and fitted for evolutionary requests as financial markets and products evolve. Legal • Set-up: given their difference in nature, the various aggregation models do not require the same steps for their creation. The aggregation models are therefore analysed in terms of the legal prerequisites necessary to enable the collection of confidential data from TRs, access to the global aggregation mechanism, governance including for storage of data and information sharing. • Data access ease and usability: given their difference in nature, the aggregation models do not provide the same level of usability to the end-users in terms of the legal steps required to access the data. The aggregation models are therefore analysed in terms of their use once the above set-up prerequisites have been established. Data • Degree of necessary standardisation and harmonisation: Standardisation can be thought of from two different perspectives: (i) the existing use of data standards or the potential to implement the use of common standards; and, (ii) the ability of a model to meet its requirements and manage legal constraints with or without the use of data standards.
In considering the second aspect, it would be important to assess the effectiveness of the model if there are no data standards and the effectiveness under partial standardisation of key identifiers. Additionally, the ability to aggregate and analyse hinges upon data elements having the same meaning and consistent content across all the TRs. Harmonisation is the means of ensuring that data content is interpreted and presented consistently.
For the purpose of assessment, it would also be important to assess the effectiveness of each model under no or partial harmonisation. • Data quality and integrity: in order to ensure a meaningful aggregation and subsequent analysis, the data subject to aggregation should be of high quality. Data quality dimensions considered in this report are completeness, accuracy, timeliness, consistency, accessibility and de-duplication. It is also important for the aggregation mechanism and processes to ensure that the data is protected against unauthorised modification.
Aspects to consider include the ability of the aggregation model to maintain data integrity and the risks to data integrity. Technology • Scalability: the aggregation mechanism should have the ability to scale to accommodate growth in scope and load and in order to manage capacity. Scalability dimensions considered include functional, processing power, data transfer and storage. • Flexibility: the aggregation mechanism should be technologically evolutionary, with flexibility embedded in the system to possibly cater for new aggregation requests. • Resilience: the aggregation mechanism should be resilient to safeguard the interests of its key stakeholders. This depends on several dimensions including the IT security 41 .
of the mechanism, the degree of dependencies on the network stability between a few or multiple points, business continuity arrangements and back-up solutions. This set of criteria is used to assess the strengths and weaknesses of the different aggregation models described in Chapter 1, considering both the level of complexity related to set-up and implementation of the different options, and the need for the solution to be effective in meeting the needs of authorities. [assessment of options to be completed after the public consultation] 7. Chapter 7 – Concluding Assessment This chapter will discuss the conclusion and recommendations of the study from its analysis of the various options for aggregating TR data to assist the FSB, in consultation with CPSS and IOSCO, in its decision on whether to initiate work to develop a global aggregation mechanism and which form of aggregation model should be used. The chapter will explain how the concluding assessment was done and how the conclusions were arrived at. The chapter will list the recommendations, including those that might point to the need for further studies, development of implementation plans as well as unresolved policy areas that might need attention from the FSB, standard setters or different jurisdictions. 42 . SECRETARIAT 22 July 2013 Appendix 1: Feasibility study on approaches to aggregate OTC derivatives data Terms of reference I. Introduction G20 Leaders agreed, as part of their commitments regarding OTC derivatives reforms to be completed by end-2012, that all OTC derivatives contracts should be reported to trade repositories (TRs). The FSB was requested to assess whether implementation of these reforms is sufficient to improve transparency in the derivatives markets, mitigate systemic risk, and protect against market abuse. A good deal of progress has been made in establishing the market infrastructure to support the commitment that all contracts be reported to trade repositories. As noted in the FSB’s April 2013 OTC derivatives progress report 1, at least 18 TRs have been established to date, located across ten jurisdictions, with some intended to operate internationally and others purely domestically. However, further study is needed of how to ensure that the data reported to TRs can be effectively used by authorities, including to identify and mitigate systemic risk, and in particular through enabling the availability of the data in aggregated form. The CPSS-IOSCO consultative report on authorities’ access to TR data, published on 11 April 2013 2, notes that: “With the current structure of TRs, no authority will be able to examine the entire global network of OTCD [OTC derivatives] data at a detailed level.
In addition, it is likely that OTCD data will be held in multiple TRs, requiring some form of aggregation of data to get a comprehensive and accurate view of the global OTC derivatives market and activities. Absent that, the financial stability objectives of the G20 in calling for TRs might not be achieved. In light of these limitations, the opportunity for a centralized or other mechanism to provide global aggregated data, as a complement to the direct access by the different 1 Available at http://www.financialstabilityboard.org/publications/r_130415.pdf 2 Available at http://www.bis.org/publ/cpss108.pdf 43 . authorities to TR held data, probably warrants consideration and further investigation, although beyond the scope of this report 3”. The FSB’s April 2013 OTC derivatives progress report follows up on this suggestion by recommending that further international work should take place on: “the feasibility of a centralised or other mechanism to produce and share global aggregated data, taking into account legal and technical issues and the aggregated TR data that authorities need to fulfil their mandates and to monitor financial stability.” Achieving global aggregation of data may involve several types of aggregation of transaction data: within individual TRs, across TRs and across jurisdictions. To successfully produce and share globally aggregated data, the following elements would need to be addressed to achieve successful aggregation of the TR data to meet regulatory objectives: – definition of the data to be aggregated; – sufficient standardisation of data formats to enable aggregation; – reconciliation of data (for instance, to avoid double-counting and gaps); – establishment of a mechanism(s) for the production of data in aggregated form, supporting the availability of summarised and anonymised data where relevant; and – provision of access to authorities as appropriate. The feasibility study will build upon and take forward the previous work done by other groups, including the January 2012 CPSS-IOSCO report on OTC derivatives data reporting and aggregation requirements 4 and the April 2013 CPSS-IOSCO consultative report on authorities’ access to trade repository data. II. Objectives of the study The feasibility study should set out and analyse the various options for aggregating TR data. For each option, the study should: 3 The CPSS-IOSCO report text added the following here in a footnote: “For performing macro assessments, or supporting provision of data for systemic risk analysis, it is probably worth investigating the feasibility of how a centralised or other mechanism would be able to collect position level and transaction level data from TRs globally and aggregate, summarise and ensure anonymity of the data, subject to applicable local law. The granularity of data could entail breakdowns by jurisdictions and counterparty types. Such a mechanism could support making the data available to all relevant authorities in standardised reports on a regular basis, that would parallel and could learn from, for example, the international financial statistics or the OTCD survey data. It could also facilitate publication of a set of aggregate data.” 4 The January 2012 CPSS-IOSCO report stated: “Work to develop a standard product classification system for OTC derivative products is needed as a first step towards both a system of product identifiers for standardized instruments and an internationally accepted semantic for describing non-standardized instruments.
The Task Force recommends that CPSS-IOSCO or the FSB make a public statement calling for the timely industry-led development, in consultation with authorities, of a standard product classification system that can be used as a common basis for classifying and describing OTC derivative products. Therefore, the Task Force recommends that the FSB direct, in the form and under the leadership the FSB deems most appropriate, further consultation and coordination by financial and data experts, drawn from both authorities and industry, on a timely basis concerning this work.” 44 . • set out the steps that would need to be taken to develop and implement the option, • review the associated (and potentially interdependent) legal and technical issues, and • provide a description of the strengths and weaknesses of the option, taking into account the types of aggregated data that authorities may require and the uses to which the data might be put. The information and technical analysis in the study will provide an important input to assist senior policy-makers in their decision on whether to initiate work to develop a global aggregation mechanism and which form of aggregation model should be used. The options for aggregating TR data to be explored by the study include: 1. A physically centralised model of aggregation. This typically involves a central database (hub) where all the data are collected from TRs, stored and subsequently aggregated within the central database for onward provision to authorities as needed. 2. A logically centralised model of aggregation based on federated (physically decentralised) data collection and storage. Logical centralisation can take a number of forms but the key feature is some type of logical indexing mechanism that enables the use of technology to aggregate data from local TR databases rather than the use of a physically central facility. In this option the underlying transaction data remains in local TR databases and aggregated with the help of the central index (using pointers to local databases).
One variant of logical centralisation is a model where the data is collected and stored locally but, instead of authorities using the logical indexing mechanism themselves to obtain the data from local databases, there is a designated agent that maintains the central index and the platform for responding to requests from authorities. 3. Collection of raw data from local TR databases by individual authorities that then aggregate the information themselves within their own systems. Other aggregation models could also be explored, as the study group considers appropriate. III. Components of the feasibility study The feasibility study should begin with a brief stocktake of the current use of TRs for reporting of transactions, including the number and location of TRs as well as utilized data reporting templates and standards, so as to provide information on the current state of the distribution of TR data that would need to be aggregated. The stocktake should draw wherever possible on existing information on current availability and use of TRs (for instance in the FSB’s OTC derivatives progress reports and the information collected through CPSSIOSCO monitoring of the implementation of PFMIs). The stocktake should also incorporate information (where known) on additional TRs that are planned but not currently operational, and of the likely implications of reporting requirements that are still under development in several jurisdictions for the use of TRs.
This brief stocktake will be needed in order to provide some background on the scale and scope of the aggregation challenge. The study should then address the following interrelated issues for each aggregation option set out above: achievement of the high data quality and consistency that authorities need from aggregated data, including appropriate data standardisation requirements and reconciliation 45 . mechanisms; data access and associated legal issues (including anonymisation of data where relevant); and the analysis of technical, organisational, operational and implementation issues associated with each model. (The ordering and length of description of each issue below is not intended as an indication of the relative importance and amount of the work to be done in the feasibility study.) III.1 Quality and consistency of data including appropriate data standardisation and reconciliation: It is difficult to aggregate data (within a single TR and across TRs nationally or globally) without consistent definition and representation of the data elements to be aggregated. This consistency could be achieved either in the initial reporting of transactions to TRs or through translation of the data into more globally consistent representations during the aggregation process. The study should make an initial analysis of the extent to which aggregation would be possible with the data that will be available under current reporting requirements to TRs. It should identify possible obstacles to the ability to globally aggregate data that may arise from the gaps, inconsistencies or incompatibilities in the data fields, definitions or formats that market participants report to TRs.
Identifying the current scope for aggregation and the obstacles will require an initial stocktaking of data field requirements and definitions and data formatting requirements in multiple jurisdictions, including whether these requirements are codified in law or regulation. The study should also analyse what would constitute a core set of OTC derivatives data elements that, if available in sufficiently standardised form, would enable the aggregation of data among TRs to support regular monitoring as well as other types of analysis by authorities, including of systemic risks. (Such a core data set could then be expanded over time if necessary.) The study should also consider possible approaches to standardising that data. In this regard, the study should draw upon recommendations in the January 2012 and April 2013 CPSS-IOSCO reports and also the work of the FSB’s OTC Derivatives Data Experts Group (ODEG), which considered the data needs of the official sector users of OTC derivatives data. Although the study’s analysis would be directed at standardisation needs in relation to establishment of a global data aggregation mechanism, it may also be relevant to recall a recommendation of the January 2012 report that, in addition to the creation of a system of legal entity identifiers (LEIs), international work be undertaken to develop an international product classification system for OTC derivatives to provide a common basis for describing products.
5 5 The January 2012 CPSS-IOSCO report stated: “Work to develop a standard product classification system for OTC derivative products is needed as a first step towards both a system of product identifiers for standardized instruments and an internationally accepted semantic for describing non-standardized instruments. The Task Force recommends that CPSS-IOSCO or the FSB make a public statement calling for the timely industry-led development, in consultation with authorities, of a standard product classification system that can be used as a common basis for classifying and describing OTC derivative products. Therefore, the Task Force recommends that the FSB direct, in the form and under the leadership the FSB deems most appropriate, further consultation and coordination by financial and data experts, drawn from both authorities and industry, on a timely basis concerning this work.” 46 .
The study should also analyse approaches (whether through data standards, reporting guidelines, or otherwise) to avoid the double-counting of transactions through the aggregation process which might arise where transactions are reported to more than one TR or reported more than once to the same TR (for instance because both counterparties to a transaction separately report the transaction). Among the questions that the study group should address are the following: – Which of the data being reported to TRs needs to be reported and stored in a sufficiently consistent and standardised form that it can be easily and accurately aggregated for financial stability monitoring and other purposes? It could also take into account the potential need in some cases for authorities in their financial stability analysis to combine aggregated OTC derivative data with data (gathered from other sources) on exchange-traded products or cash instruments. – What types of data aggregates might authorities require for financial stability monitoring and other purposes (in light of the recommendations in the CPSS-IOSCO TR Access Report)? – Does the data need to be reported in a globally consistent manner to TRs in the first place to make accurate global aggregation of the data feasible, or is it possible to develop a translation mechanism that will permit the aggregation of data originally provided in different formats? Are there any legal issues related to such translation? Do the answers to these questions differ between the different aggregation models? – How can data standardisation best be achieved (for example by setting international standards for reporting of data to TRs, or by coordination between national authorities)? – What are other elements that need to be standardized to achieve data aggregation such as business rules for producing the data content (e.g. data dictionaries); operational and technology standards for data normalisation/harmonisation, transfer, error handling and reconciliation? – How can data be reconciled, so as to avoid double-counting and gaps in aggregated data? How might aggregation mechanisms address data quality problems that could undermine the usefulness of aggregated data? – Should values be converted to a global currency to allow for cross-currency aggregation? III.2 Data access and associated legal issues for each aggregation model: In considering the feasibility of each aggregation model, legal issues need to be considered, including the legal ability for data to be provided to the aggregating mechanism, as well as the legal ability of the aggregating mechanism to produce and share data with appropriate authorities. In considering these issues, the study group should draw upon the experiences and solutions found by other international data gathering exercises? Among the questions that the study group should address are the following: – What (if any) legal or procedural issues would there be in ensuring data can be sent from TRs into the aggregating mechanism? What requirements may this put on an 47 . aggregating mechanism to ensure data security is maintained? How do these legal issues differ between the different options for aggregating mechanisms? – What legal and procedural issues would need to be addressed with regard to the production and sharing of aggregated data under each of the models? How might privacy and confidentiality issues and any other restrictions affecting authorities’ access to TR data, such as indemnification requirements, affect the modalities for making aggregated data available under each of the options, either in terms of passing on aggregated data to a hub or providing the information to authorities? 6 – Are these issues affected by whether the data are obtained by domestic or foreign authorities directly from TRs, from a hub, or via other authorities? How do those issues differ according to the scope of aggregation (for example, at a national or cross-border level or the form in which the data is being provided, e.g. anonymised or summarised)? – Are there additional legal issues in cases where authorities may also require access the original data before aggregation, or may require access in a form that gives them flexibility to able to aggregate it in different ways (for instance by subsets of products or market participants)? – What types of agreements could be needed to support each aggregation model? To what extent are data access and sharing needs covered by existing information sharing agreements, or are further agreements likely to be needed? How can questions of data security be dealt with? – What are important preconditions in each jurisdiction related to data provision and use (e.g., multilateral or bilateral MoUs)? How would legal prohibitions, limitations, or preconditions affect the structure of the aggregation mechanism? How can such legal prohibitions, limitation, or preconditions be overcome via different operational solutions? – Are there circumstances in which, for legal reasons, data may need to be aggregated first at a national level before cross-border aggregation takes place? III.3 Analysis of technical, organisational and operational issues of each aggregation model: For each of the possible approaches to providing globally aggregated TR data to authorities, the study should examine the operational implications and issues, taking into consideration: – existing TR infrastructure and data reporting standards; – data privacy and confidentiality considerations, building on the work already conducted on these issues in the area of OTC derivatives and bearing in mind the different categories of data users amongst authorities; 6 Issues arising from current privacy and confidentiality restrictions on the reporting of data to TR and on the reporting of TR data to authorities are surveyed in the FSB’s April 2013 OTC derivatives progress report. This feasibility study should consider any issues arising for the aggregation model from such restrictions. 48 . – local languages and variations in existing national approaches to the representation of trades; – the governance of the mechanism; including the relationship with overseers of TRs; – important practical aspects, such as time to implementation, technological requirements, operational reliability, adaptability and cost efficiency. IV. Composition of the feasibility study group The feasibility study group is to be co-chaired by experts from member organisations of CPSS and IOSCO. The composition of the study group is to be ad hoc including, in addition to experts from CPSS and IOSCO members, other experts from organisations not represented in these bodies that have roles in macroprudential and microprudential surveillance and supervision and the FSB Secretariat. The group should include a balanced representation of a range of expertise, covering aspects such as: – data fields and formats; – the potential needs of and uses by authorities of aggregated data; – legal and regulatory considerations; – IT and other technical issues. At the same time, the number of members should be limited to approximately 20 people, to enable the study group to work expediently. The Secretariat for the study group will comprise members of the CPSS, FSB and IOSCO Secretariats. The tight timeline and the potential interrelationships between data and legal issues imply that these two sets of issues should be explored in parallel. The study group should therefore set up two subgroups to consider respectively the technical data issues and the data access and legal issues.
(This would be similar to the approach taken in the FSB’s Data Gaps Implementation Group that is implementing a common data template for G-SIFIs.) These groups should coordinate closely in real time, through having some members in common, common secretariats and sharing of working papers, to ensure that interrelationships between the two sets of issues are taken account of. They should involve additional experts beyond the study group members as needed. The study group may also set up other workstreams in specific areas as it sees fit, which may involve additional experts in specific areas. V. Schedule and deliverables The group will need to work under an accelerated timeline, given the importance of rapid completion of the G20 reforms and effective use of TR data by authorities. The group should provide progress reports on the status of the work to the FSB, and for information to CPSS and IOSCO, including an interim report before end-September.
The group should prepare a 49 . draft report by mid-January 2014 for review and approval by the FSB, with a view to requesting public feedback beginning no later than mid-February 2014. The final report should be provided to the FSB no later than end-May 2014 and will subsequently be published. The FSB, in consultation with CPSS and IOSCO, will then make a decision on whether to initiate work to develop a global aggregation mechanism and, if so, according to which type of aggregation model and which additional policy actions may be needed to address obstacles. In taking forward the work, the group should engage with market participants and market infrastructure providers, having regard to geographical balance as well as with firms in the non-financial sector that have had successful experience in building functioning uniform global data infrastructure systems. As part of this engagement, the group should consider whether to host a workshop to discuss each aggregation model, its pros and cons and implementation approaches as part of its analysis. 50 . OFFO Appendix 2: Summary of the outreach workshop FSB Aggregation Feasibility Study Group (AFSG) outreach workshop Summary of the meeting in Basel 13 November 2013 The FSB AFSG Industry Workshop was conducted in Basel, Switzerland on November 13, 2013. The purpose of the workshop was for the AFSG membership to understand industry perspectives, approaches and practices to aggregation and apply those to the development and assessment of the different options for Trade Repositories (TR) aggregation being considered by the group following the FSB mandate. I. Opening remarks The co-chairs of the FSB feasibility study group on approaches to aggregate OTC derivatives data, Mr Benoît Cœuré (ECB) and Mr John Rogers (US CFTC) welcomed the outreach workshop participants. They noted that the purpose of the event was to learn about various options of the data aggregation from different aspects. The specific objective of the workshop was to assist the group in its work to identify the pros and cons of mentioned three options for aggregation: 1. A physically centralised model of aggregation. 2. A logically centralised model of aggregation based on federated (physically decentralised) data collection and storage. 3. Collection of raw data from local TR databases by individual authorities that then aggregate the information themselves within their own systems. The co-chairs indicated that the workshop would address both technical and legal issues in relation to the implementation of the alternative options, and the AFSG had invited attendance of experts with expertise in the range of issues involved, including data, IT and legal issues. II. Panels to discuss current approaches to data aggregation (inside and outside the financial sector) A. A physically centralised model of aggregation Panellists: Trade Repository Limited, LSE, SAMA-TR The panel on physically centralised model of aggregation focused on how the model would be defined, what the pros and cons are and what the potential hurdles for implementation are and how to overcome them.
The panellists presented their experiences and advise on the aspects to consider in developing and assessing such a model. 51 . The current data aggregation challenge was presented where aggregated number of reports is not equal to the market’s exposure. That creates an issue of how the data aggregated from TRs actually allows regulators to meet various regulatory needs. The objectives of instrument/product data were enumerated in order to achieve regulatory data use: global scale, multiple purpose, automated analysis, automated aggregation, cross market focus. The participants suggested that a semantic representation using a concatenation of standardised building blocks can be helpful to overcome the global data aggregation challenge.
It was noted that with source data (i.e. data that can be aggregated) and timely additive partial composites, the meaningful observations of changes to market flows and exposures are readily available just days after trades are done and that even with limited coverage this enables better market oversight and systemic risk analysis and management. Participants also stated that before going into selection of aggregation models the following questions need to be answered: Are all the current derivative reporting regulations compatible? How do you ensure data is not duplicated? How is access to data governed and approved? What can be done to ensure the consistency of the data? What is being aggregated? Participants emphasised that governance is one of key dimensions of a physically centralised model. It was also mentioned that when implementing a physically centralised model on the local level, the unavailability of standardised taxonomies for the contracts was a challenge. Consequently, the TRs had to develop standards and shared them among reporting entities. That facilitated the ability to aggregate and compare the reported data. Participants also explained their experiences in implementing and developing standards that would assist in the harmonisation and description of complex OTC derivatives data which would in turn assist aggregation efforts. The participants also explained their experiences and challenges in implementing the model under different circumstances including management of stakeholders, technical planning, project planning, access governance, project management as well as technical implementation. B. A logically centralised model of aggregation based on federated approach Panellists: ANNA, GS1, Quartet FS, DTCC, Denodo The session focused on the logically centralised model of aggregation based on a federated data collection and storage.
The objective was to answer the following questions: What is the logically centralised model? How can it be implemented? What are the obstacles and how can they be overcome? Participants made it clear that several variants might exist under the logically centralised model label. While such model is in essence characterised by the combination of data remaining stored in local repositories and the existence of an index, the scope of the data contained in that index may vary widely. On one extreme the index may be populated with only a list of identifiers with pointers to the local repositories.
In such a scenario, the index would not store actual data but only references. However, when the data get complex - and also depending on the complexity of the queries - the index would have to store (cache) some data for the mechanism to produce the expected outcome. In any case, it is a key that the index can be trusted and is thus properly governed.
As an overall consequence, participants considered that a logically centralised model can mitigate some legal issues 52 . compared with a centralised model when processed data are confidential, but the extent to which it could achieve this would ultimately depend on the data held in the index and the nature and of oversight/supervision or governance of the index operator. In the context of financial transactions, participants considered whether it was likely that the aggregation mechanism would require more data held in some version of a centralised unit in order to perform indexing. In this respect, participants underscored that the nature of the data processed - whether public as in the LEI framework or private and confidential as data held in TRs - would be a key matter to bear in mind. Some participants opined that the logically centralised model might not be the most efficient one for complex queries. They also highlighted the need to make the aggregation mechanism flexible and scalable. For example, participants made clear that the mechanism should be flexible regarding the incorporation of new queries and further (new established) TRs.
Some participants stated that they would not recommend pre-aggregation of data and advised that the aggregation mechanism should use the raw transactional data to produce the aggregated outcome of good quality. More generally, and beyond the issue of the model to be adopted, participants noted that a clear identification of the objective of the aggregation with a distinction between local regulatory objectives and global ones would help to identify the granularity of the data needed as well as governance model. However, they admitted that the use of raw data raises a number of the issues on confidentiality and volume/cost issues that should not be ignored. In addition, they opined that the use of raw data may also increase the expectations on the role of the index and its operator, or at least of the rules that entities using the index should follow (to ensure harmonised aggregation). Some participants highlighted that the distinction between the content of the data to be captured and the move of the data among the interested parties (”choreography”) is an important feature of a logically centralised model.
In order for the model to work and to provide good-quality data, the participants felt that content has to be clearly defined and be the same among the actors of the model regardless of the choreography, while choreography might vary based on circumstances. In contrast, there might be different styles of choreography (where the data reside, when and how they move between partners, regulators, repositories) with a need to be able to change the choreography to match varying processes. Regarding the content, and in the context of financial transactions, participants observed that product scope varies by jurisdictions, including the definition of derivative contracts. Therefore, they expressed that there is a need for regulators to look at open sources and standards supported by industry stakeholders - and to promote globally recognised identifiers wherever possible. Participants felt that adequate procedures (criteria for membership, regular (standardised) report) need to be in place to generate trust. Finally, participants mentioned several additional benefits of the logically centralised model, in terms of scalability, tailoring to local needs and cost reduction through competition, but also warned that many initiatives have failed due to costs. 53 . C. Data collection and aggregation by users from local sources Panellists: ACTUS, NSD, ICE, Bloomberg, NOAATS, CME Group Panellists presented their views on data collection and aggregation by users from local sources and potentially at local level. It was noted that the objective of aggregation is to get meaningful financial analytical information. Simple aggregation of disparate financial instruments does not support this objective because there is no common metric to support such aggregation. It is akin to trying to add apples and oranges.
Meaningful financial analytical information is derived from the ability to understand how changes in risk factors affect value, income, liquidity, and stress tests. Such analyses start with the ability to represent how changes in risk factors affect the cash flows associated with individual financial contracts. The example of algorithmic contract types unified standards (ACTUS) was introduced to solve this problem.
It is being developed to generate the common metric of state contingent cash flows for all financial contracts. Such state contingent cash flows are the starting point for a broad range of financial analyses. These analysis results can then be aggregated for any size pool of financial obligations -- portfolios, single institutions, individual markets, or the financial system -- to yield meaningful financial analytical information. Participants expressed the view that the following core principles for the TRs needed to be introduced to guide the feasibility analysis: (a) transparent and high standards governance; (b) minimal operational processing; and, (c) adherence to current and future rules of regulatory authorities.
That would require common data on counterparties; products, trades, venue(s) of execution, price, quantity, Central Counterparties (CCPs) at minimum. For the purpose of data aggregation the TRs face a number of challenges that need to be addressed such as collection of accurate data, clarity on fields being reported to TRs; data harmonisation where there is a lack of consistency among TRs on the interpretation of data requirements. Data security was emphasised as a key consideration. Participants also described the common ETL (extract/transform/load) approach that could be applied for data aggregation: (a) extraction of external data from sources; (b) transformation/conversion of external data into internal target format where data needs to be normalised so it can be aggregated and accurate meaning can be inferred from it; and, (c) finally load of useable data to target database.
Different depths of access were introduced for different data types to achieve aggregation purposes. Participants noted that local/federated type data aggregation might work. Data sharing between authorities could be done using standard framework under reciprocal agreement – however legal issues would need to be addressed in terms of what can be shared across jurisdictions.
Different views were presented on what model is more expensive for implementation and long-run maintenance. Panellists emphasised that while legal and technical issues on collecting transaction level data by each local TR could be addressed with relatively less effort, global collection and aggregation of OTC derivatives data could raise many issues between countries and various stakeholders within each country depending on the access level. As a practical way forward, equal accessibility by every country to the data was suggested. In this context accessibility means literal ability to access global data and capability of an authority to achieve its goal by using the data.
The participants felt that UPI system standard was vital for data aggregation. 54 . III. Data considerations Panellists: FIBO, FIX, FpML, ISO The panel on Data Consideration discussed matters related to data and data standards and how to leverage them for aggregation. Participants noted a number of times that data standardisation was a key tool for data aggregation. They also noted that the focus should be on standardisation of content rather than on formats. Participants noted that the biggest standards gap is in the area of financial language and unambiguous shared meaning (definitions).
They also noted that existing standards used by (participants/TRs/regulators) can be leveraged if mapped to a common meaning. Panellists also elaborated on the difference between semantics and syntax of standards. They noted that terminology plays a major role in understanding semantics and that a common terminology with definitions and ‘translations’ would be helpful here. They further noted that without standards for counterparties, instruments and trades, it would be hard to make quick progress in data aggregation.
Counterparties and instruments might be subject to a hierarchical structure and relationships between entities may be of interest when aggregating data. Participants stated that reporting of aggregated data requires an upfront and detailed specification, and noted that if such a specification is ambiguous, it might result in a lack of harmonisation and, worse, in misaggregation and thus unreliable data. Participants stated that reporting of transaction level data is easier as it is primarily about passing through data from market participants yet they noted that it raises more confidentiality and thus governance issues. Participants also introduced their ideas about structure of UTIs and UPIs.
In particular, they noted that UTI generation and communication should occur at earliest possible point in trade flow. One of the suggestions was to use a prefix in UTI construct focused on utilizing the CFTC USI namespace in the construction of the UTIs. With respect of to the UPI, one of the suggestions was to use ISDA OTC taxonomy.
Under this model, they noted that the ISDA Asset Class Implementation Groups and Steering Committees proposed and approved this governance structure. It was also suggested that no country- specific IDs should be used and that only global codes, such as the LEI, should be used. It was also noted that there is a need for collaboration between regulators and endorsement by regulators of the development of a unique global trade and product identifiers.
Otherwise, we risk having multiple identifiers, which defeat part of the purpose and will make the work of aggregation more difficult. Furthermore, participants suggested that existing identification and classification schemes should be used as far as possible. They noted the experience of common data dictionaries under ISO 20022 (ISO 20022 “Investment Roadmap” integrated FIX, FpML, ISO (MT/MX) and XBRL into a common framework). It was also noted that only open- access and nonproprietary standards should be used in order to avoid competition issues and not to discriminate against smaller operators. 55 .
IV. A. Legal considerations in data aggregation Panellists: ISDA, STET, DTCC, BM&FBOVESPA The session focused on the potential legal issues that might arise from the data aggregation framework. Firstly, participants pointed out existing legal issues such as privacy and confidentiality, intellectual property, indemnification, and data access. An example of the centralised hub for derivatives introduced in Brazil (due to their 3 TRs) was presented to participants.
The Brazilian system also includes valuation data and the registration in a TR is a condition for legal validity of the contracts. With regard to data aggregation schemes, participants asked for more clarity on which authorities have access to what kinds of data and for what mandate. In order for authorities to share the data, while ensuring the data security/protection, participants suggested that authorities might want to consider establishing a framework of multilateral MOU, possibly leveraging MoUs such as IOSCO Multilateral MOU. Though participants noted that anonymisation could help to solve the confidentiality issue, they questioned how authorities could aggregate and properly use such data for assessing and monitoring systemic risk and monitoring financial markets in general without names or unique identifiers. Also they noted that the method of anonymisation needs to be consistent amongst TRs.
One of the proposals was to establish a harmonised model to regulators as they bear a general duty to keep data confidential while ensuring regulators get access to the data appropriate to their mandates. This could also be extended to the public, in aggregate form (data dissemination duty). Some participants felt that legal issues might be less complicated if the data could be aggregated and then distributed to authorities than a case where providing authorities are provided with direct access to detailed data however others disagreed with the position.
Participants also noted that different jurisdictions have different requirements for OTC derivatives reporting (e.g. US position reporting versus EU reporting of contracts, the latter putting the responsibility to calculate positions on the TRs themselves). Some participants noted that the data level of detailed data depends on the purpose of data collection and suggested that if the purpose of data aggregation is to have general view of the OTC derivatives markets, classification such as banks, hedge funds, pension funds etc. might suffice to support such an objective. Regarding individual clients (natural persons), participants pointed out that reporting requirements vary from country to country.
They noted, for example that, in Japan, in a case where counterparty is not a bank, it is not necessary to report specific names but only classification as ‘client’. The participants argued that, given the large volumes of data, it might be enough to collect and analyse the data of relatively large reporting firms (e.g., top-ten firms and top-ten counterparties). They opined that if authorities observed any potential risk, then the relevant national authorities could have access to the raw data to analyse at a deeper level. In that sense, collecting data from large entities would possibly satisfy the need/objective to analyse the systemic risk. Participants noted that generally there exists no legal intellectual property (IP) rights on raw data but data aggregated by TRs could be protected pursuant to the relevant IP rules and laws. 56 .
The term 'ownership' was discussed regarding data access rights. One commenter suggested that TRs only have the rights to use the data as described by regulations the legal and contractual rules under which they operate. This is an important factor on disclosure of data as TRs do not own the data they received and are bound by a legal obligation of confidentiality towards their clients by its participants and under regulation. Participants recalled that authorities have access to the data held at TRs in their jurisdictions, for their specific mandates. In addition, in the cross-border context, authorities have access to the data to fulfil their mandates based on the CPSS-IOSCO Access Report.
In these cases, confidentiality is still an issue since the data needs to be kept secure (in authorities’ domain). IV. B. Technology considerations Panellists: Denodo, PRMIA, Sapient, TriOptima In this section participants focused on technology considerations for analysis of data aggregation models. Among technical dimensions, data standards, aggregation methodology and system architecture were outlined.
On the business and policy dimensions participants discussed commercial incentives, practical reality and political will as well as trust. Participants also noted the overlapping dimension of the access choreography that needs to be carefully structured. The docking model of financial data compression was introduced where the transaction aggregation systems provide access via extraction, transformation and load to granular data that is being aggregated via tuneable, multi-dimensional processor. Participants introduced the idea of service centres which harvest and manage data from various repositories. It was noted that the challenge of complex structured deals would be addressed by the opportunity of visual data navigation tools.
Participants emphasised that data size is not a real issue but data standardisation, cost and complexity are the issues to focus on. Participants introduced data virtualisation. This approach decouples data complexities from the business logic; defines canonical data models for business units; utilises central governance for security and data lineage, provides data on demand either via cache or scheduled batch; allows reuse of models which are easy to transform, combine and change data, reduces replication costs; and integrates with existing tools. Participants also discussed the concept of exposure and repository reconciliation. They identified five important targets when discussing technical considerations and conceptual architecture: scalability, availability, confidentiality, integrity and sustainability. Participants made a distinction between two data aggregation models from the standpoint of anticipated analysis - reactive approach versus a proactive approach.
In reactive approach analysis is undertaken when triggers locally require an extended scope of analysis. Participants felt that from this standpoint it reduces resilience requirements as system uptimes are required for retrospective forensic analyses rather than real time monitoring. Participants discussed whether repositories’ primary purpose is for storage and forensic analysis. Participants stated that for valuable forensic analysis, a complete non-aggregated record is preferred with low data sharing restrictions. On the other hand, proactive approach provides for configured analytics trending on data to highlight potential risks.
Here resilience requirements are increased as analytical success is dependent on robust data delivery. Participants stated that in this case, the primary purpose is to highlight trends of concern. 57 . Participants noted that at the same time data sharing and aggregation can be restricted to satisfy extra territorial restrictions and harmonised canned reports required to push trend and analytics data to regulators. V. Summary of takeaways from subgroup discussions and closing remarks The co-chairs thanked the workshop participants for their insights and professional opinions which would be a useful basis for the FSB group AFSG analysis. They encouraged participants to provide further comments on the consultative report of the group to be released in February 2014 as a continued engagement in the public-private consultation process. 58 . List of private sector participants for the FSB outreach workshop on approaches to aggregate OTC derivatives Basel 13 November 2013 Bloomberg L.P. Ravi Sawhney Head of Fixed Income Credit Trading BM&FBOVESPA Marcelo Wilk OTC Operations Officer The Central Securities Depository Leszek Kolakowski Vice Director, Strategy and Business Development of Poland (KDPW S.A.) Department Kinga Pelka Specialist, Trade Repository Department CME Group Jonathan Thursby President, CME Swap Data Repository Denodo Technologies Gary Baverstock Regional Director, Northern Europe FIX - Deutsche Börse AG Hanno Klein Senior Vice President DTCC Marisol Collazo DerivSERV FIBO - EDM Council, Inc Michael Atkin Managing Director Fincore Ltd Soeren Christensen CEO George Washington Law School University Navin Beekarry Researcher, Lecturer GS1 Kenneth Traub Standards Strategy Consultant Intercontinental Exchange Kanan Barot Director, Ice Trade Vault Europe ISO - Investment Management David Broadway Senior Technical Adviser Association 59 . ISDA Karel Engelen Director, Global Head Technology Solutions ISDA - Deutsche Bank Stuart McClymont ISDA data and reporting steering committee KOSCOM He Young Jun Assistant Manager, Global Business Department Gi Young Song Assistant Manager, System Department LCH.Clearnet. Ltd Richard Pearce Business Change Manager, SwapClear London Stock Exchange Group James Crow Head of Product Solutions & Development (LSEG) Neil Jones Product Solutions Architect ANNA - Malta Stock Exchange Stephanie Galea Senior Manager, Compliance & Market Operations Mizuho Bank Ltd Satoru Imabayashi SVP and Head of Planning, Market Coordination Div. National Settlement Depository Pavel Solovyev Head of Trade Repository Development NOA ATS Kibong Moon CEO Nomura Kieron O’Rourke Global Head of OTC Services Project ACTUS Allan Mendelowitz Strategic Adviser QUARTET FS Catherine Peyrot Senior Sales Executive David Cassonnet Program Director REGIS-TR Mari-Carmen Mochon Project Manager 60 . RTS Alexandra Kotelnikova Chief Expert, Regulatory Support Department Sapient Global Markets Cian O’Braonain Regulatory Reporting Practice Global Lead Peter Newton Senior Manager, Markets Infrastructure Initiatives Saudi Arabian Monetary Agency Abdulaziz Alsenan Project Manager, General Department of Payment Systems Mohammed Al Hossaini General Department of Payment Systems STET Fabienne Pirotte Legal Counsel Sumitomo Mitsui Banking Corporation Kenji Aono Deputy General Manager, Corporate Risk Management Dept SWIFT Yves Bontemps Head of Standards R&D PRMIA - Tahoe Blue Jefferson Braswell CEO, Founding Partner The Trade Repository Ltd Marcelle Kress von Wendland CEO Traiana Ltd Mark Holmes Programme Manager TriOptima Henrik Nilsson Head of Business Development 61 . OFFO Appendix 3: Extract from the Access Report (Table 6.2) Assessing systemic risk (examining size, concentration, interconnectedness, structure) Evaluating derivatives for mandatory clearing determinations and monitoring compliance with such determinations Evaluating derivatives for mandatory trading determinations and monitoring compliance with such determinations Definition An authority with a mandate to monitor a financial system and to identify emerging risks An authority that has a mandate to evaluate OTCD for mandatory clearing determinations and monitoring its implementation An authority that has a mandate to evaluate OTCD for mandatory trading determinations and monitoring its implementation An entity that has a mandate to foster and support financial stability globally An authority that has a mandate to conduct market surveillance and enforcement Typical depth of data required Transaction-level Transaction-level Transaction-level Position-level Transaction-level Typical breadth of data required All counterparties (1) Any transactions in which one of the counterparties is within its legal jurisdiction and (2) all transactions on the underliers (i) within its legal jurisdiction (whether the counterparties are in the jurisdiction or not), (ii) for which the authority considers making or makes a mandatory clearing determination, or (iii) any transactions involving the same type of OTCD contract as the one being evaluated (whether the counterparties or underliers are in the jurisdiction or not) (1) Any transactions in which one of the counterparties is within its legal jurisdiction and all (2) transactions on the underliers (i) within its legal jurisdiction (whether the counterparties are in the jurisdiction or not) or (ii) for which the authority must make a mandatory trading determination All counterparties Any transactions for counterparties in its legal jurisdiction as well as branches or subsidiaries of these counterparties which may be in other jurisdictions, and all transactions on the underliers within its legal jurisdiction (whether the counterparties are in the jurisdiction or not) Identity Named data for counterparties and underliers within their legal jurisdiction. Anonymised data for other counterparties Anonymised counterparties and named data where named data are required for evaluating determinations; named data for monitoring compliance with such determinations Anonymised counterparties and named data where named data are required for evaluating determinations; named data for monitoring compliance with such determinations Anonymised Named data 62 General macro assessment Conducting market surveillance and enforcement . Registering and regulating market participants and supervising market participants with respect to business conduct and compliance with regulatory requirements Prudentially supervising financial institutions Supervising/ overseeing exchanges, organised markets and organised trading platforms Regulating, overseeing and supervising payment or settlement systems Regulating, overseeing and supervising CCPs Regulating, overseeing and supervising TRs Definition An authority that has a mandate to supervise market participants. An authority that has a mandate to supervise and regulate or to monitor and conduct surveillance on the financial institution An authority that has a mandate to supervise exchanges, organised markets and organised trading platforms An authority that has a mandate to oversee a payment or a settlement system An authority that has a mandate to supervise or oversee a CCP An authority that has a mandate to supervise a TR Typical depth of data required Transaction-level Transaction-level Transaction-level Transaction-level Transaction-level Transaction-level Typical breadth of data required Transactions in which one of the counterparties, whether registered or not, is within its legal jurisdiction, or in which one of the counterparties engages in OTCD transactions with, or whose OTCD transactions are guaranteed by, an entity within its legal jurisdiction (whether the counterparties are in the jurisdiction or not) Transactions in which one of the counterparties is a consolidated organisation whose parent is supervised by the authority, including all subsidiaries, domestic or foreign, of the entity Any transactions traded on an exchange, organised market or organised trading platform supervised by the authority Any transactions settled by a payment or settlement system overseen by the authority Any transactions that are cleared by a CCP supervised or overseen by the authority Any transactions reported to the TR Identity Named data Named data Named data Anonymised transactionlevel data as a general rule, but named positionlevel data for the counterparties of the central bank and where investigation of suspicious activity is needed. Named data Named data 63 . Planning and conducting resolution activities Managing currency policy Implementing monetary policy Lender of last resort function Definition An authority that has a mandate to resolve financial institutions An authority in its function as monetary policy authority An authority in its function to implement monetary policy An authority in its function as possible lender of last resort Typical depth of data required Transaction-level Transaction-level (Participants within legal jurisdiction), aggregate-level (all participants for underliers denominated in its currency) Aggregate-level Position-level Typical breadth of data required Any transactions in which one of the counterparties is the entity subject to resolution or a domestic or foreign affiliate Any transactions that specify settlement in that currency, including transactions for which that currency is one of two or more specified settlement currencies Any transactions for participants within a central bank’s legal jurisdiction or underliers denominated in a currency for which the central bank is the issuer Any transactions for which a named institution is a counterparty Identity Named data Anonymised Anonymised Named data 64 . OFFO Appendix 4: Data Elements Data elements needed to perform queries for various regulatory purposes can be classified in various ways. The list of data fields depends on the mandate of the user and shall be adapted according to the specification and particular type of the aggregation system. The diagram below shows different examples of data elements that may be used by users to perform a request. Another list of fields data elements (below) is intended to allow the user to describe the form of the result expected This includes the specification of expected data elements and of operations to be performed on the data, such as summing or counting. Depending on their mandate, some users will have limited ability to define the form of the result, for instance some of them might be obliged to perform summation over specific data elements. LEI Counterparties LEI LEI CCP LEI Range (if transaction-level) Date Final beneficiary Executing broker, clearing broker Participants Sector or counterparty type (ex.
non-financial counterparty) Between XX and XX Snapshot (if position-level) All open contracts at date XX Type of date: execution, settlement, clearing, modification of contract, termination UPI (or range of UPIs) Product Underlying Delivery type Master agreement Status Open: Y/N Cleared: Y/N From the standpoint of a user, the requests and the results need to be independent from the specific implementation of the system. The different requests described here could be performed under any of the options discussed in this report. 65 . Net/gross Position Portfolio/entity level Type: price-forming trade, intragroup… Individual data Field of the table Transaction Anonymous or not Duplicates allowed: Y/N Count Aggregation/ operations Sum For currencies: conversion into one currency (accoridng to conversion rules) or sub-results according to the various currencies Set operations Append, difference, join… 66 . Appendix 5: Glossary of Terms and Abbreviations Access Report August 2013 CPSS-IOSCO report on authorities’ access to TR data. AFSG Aggregation Feasibility Study Group Aggregated Data Data that have been collected together, but may or may not have been summed; the data could instead be available at transaction-level or position-level. Aggregate-Level Data Data that have been summed according to a certain categorisation, so that the data no longer refer to uniquely identifiable transactions. Aggregation Mechanism Mechanism designed for aggregating data. Aggregation Model Three broad aggregation models are discussed in the report: Option 1 - a physically centralised model; Option 2 - a logically centralised model; and Option 3 - the collection and aggregation by authorities themselves of raw data from trade repositories. See Section 1.3 for more details. Anonymised Data Data from which the counterparty name or other identifier have been removed. Access Rules Rules that determine which authorities have access to which information according to their mandate and confidentiality restrictions in the use of data. BIS Bank for International Settlements BCM Business Continuity Management CCP Central Counterparty Child-Trades Series of smaller orders, as opposed to “parent” or larger orders. CFI Classification of Financial Instruments CPSS Committee on Payment and Settlement Systems CDs Credit Default Swaps Data aggregation The organisation of data for a particular purpose, i.e., the compilation of data based on one or more criteria. See Section 1.5 for a more detailed discussion. 67 . Data Report January 2012 CPSS-IOSCO report on OTC derivatives data reporting and aggregation requirements. EMIR European Market Infrastructure EU European Union FMIs Financial Market Infrastructures FSB Financial Stability Board Flow Event An event such as a new trade, an amendment or assignment. G20 Group of Twenty GLEIF Global LEI Foundation G-SIBs Global Systemically Important Banks HGG Hub Governance Group. Oversees the pooling and sharing of information and is responsible for all governance aspects of the multilateral arrangement for the International Data Hub. ID Identification of underlying instrument International Data Hub An international framework that supports improved collection and sharing of information on linkages between global systemically important financial institutions and their exposures to sectors and national markets. See Box 3 of the report. IOSCO International Organization of Securities Commissions ISO International Organization for Standardization ISDA International Swaps and Derivatives Association IT Information Technology LEI Legal Entity Identifier: An LEI comprises a unique machine readable code identifying the entity, that points to a set of key reference data relating to the entity, such as the name, address, etc. (See FSB “A Global Legal Entity Identifier for Financial Markets” Report). MoU Memorandum of Understanding OTC Over-the-Counter 68 .
RED Codes Reference Entity Data Base Codes: Unique alphanumeric codes assigned to all reference entities and reference obligations ROC Regulatory Oversight Committee for the global LEI system. TR Trade Repository: TRs are entities that maintain a centralised electronic record (database) of OTC derivatives transaction data. UPI Unique Product Identifier: A product classification system that would provide each individual financial product with a unique code. UTI Unique Transaction Identifier: A transaction classification system that would provide each individual transaction with a unique code. 69 . Appendix 6: Members of the Aggregation Feasibility Study Group and other contributors to the report Co-chairs: Benoît Coeuré European Central Bank John Rogers US Commodity Futures Trading Commission Australia Jennifer Dolphin Australian Securities and Investment Commission Brazil Sergio Ricardo Silva Schreiner Securities and Exchange Commission Canada Joshua Slive Bank of Canada Andre Usche Bank of Canada Shaun Olson Ontario Securities Commission Jean-Philip Villeneuve Québec AMF China Shujing Li China Securities Regulatory Commission Zhu Pei China Securities Regulatory Commission France Priscille Schmitz Banque de France Olivier Jaudoin Banque de France Yann Marin Banque de France Sébastien Massart Autorité des Marchés Financiers Germany Sören Friedrich Deutsche Bundesbank 70 . Hong Kong Colin Pou Hong Kong Monetary Authority Pansy Pang Hong Kong Monetary Authority India Sudarsana Sahoo Reserve Bank of India Italy Carlo Bertucci Banca d’Italia Japan Osamu Yoshida Financial Services Agency Hiroyasu Horimoto Financial Services Agency Shoji Furukawa Financial Services Agency Korea Namjin Ma Bank of Korea Netherlands Rien Jeuken De Nederlandsche Bank Russia Philipp Ponin Central Bank of the Russian Federation Saudi Arabia Abdulmalik Al-Sheikh Saudi Arabian Monetary Agency South Africa Marcel de Vries South African Reserve Bank Sweden Loredana Sinko Riksbank Malin Alpen Riksbank Switzerland Patrick Winistoerfer Financial Market Supervisory Authority UK Nick Vause Bank of England Anne Wetherilt Bank of England John Tanner Financial Conduct Authority 71 . US Srinivas Bangarbale Commodity Futures Trading Commission James Corley Commodity Futures Trading Commission Cornelius Crowley Department of the Treasury Angela O’Connor Federal Reserve Bank of New York Janine Tramontana Federal Reserve Bank of New York Kathryn Chen Federal Reserve Bank of New York Celso Brunetti Federal Reserve Board European Central Bank (ECB) Simonetta Rosati Karine Themejian Daniela Russo Roland Straub European Commission Mariel Jakubowicz Julien Jardelot European Securities and Markets Authority International Organization of Securities Commissions (IOSCO) Committee on Payment and Settlement Systems (CPSS) Frederico Alcantara FSB Secretariat Rupert Thorne Irina Leonova Tajinder Singh Yukako Fujioka Klaus Martin Löber Philippe Troussard 72 . Appendix 7: List of References CPSS-IOSCO: Authorities' access to trade repository data (“Access Report”), August 2013. CPSS/IOSCO: Report on OTC derivatives data reporting and aggregation requirements (“Data Report”), January 2012. FSB: A Global Legal Entity Identifier for Financial Markets, 8 June 2012 FSB: OTC Derivatives Market Reforms: Fifth Progress Report on Implementation, 15 April 2013 FSB: OTC Derivatives Market Reforms: Sixth Progress Report on Implementation, 2 September 2013 IMF staff and FSB Secretariat: The Financial Crisis and Information Gaps - Report to the G-20 Finance Ministers and Central Bank Governors, October 29, 2009 International Organization for Standardization: ISO 22301:2012 Societal security -- Business continuity management systems --- Requirements Regulatory Oversight Committee: Charter of the Regulatory Oversight Committee for the Global Legal Entity Identifier System, 5 November 2012 73 .
The FSB, in consultation with the Committee on Payment and Settlement Systems (CPSS) and the International Organization of Securities Commissions (IOSCO), will then make a decision on whether to initiate work to develop a global aggregation mechanism and, if so, according to which type of aggregation model and which additional policy actions may be needed to address obstacles. The attached public consultation paper responds to the request by the FSB for a feasibility study that sets out and analyses the various options for aggregating OTC derivatives TR data. The draft has been prepared by a study group set up by the FSB and composed of experts from member organisations of CPSS and IOSCO and other organisations with roles in macroprudential and microprudential surveillance and supervision. The paper discusses the key requirements and challenges involved in the aggregation of TR data, and proposes criteria for assessing different aggregation models. Following this public consultation and further analysis by the study group, a finalised version of the report, including recommendations, will be submitted to the FSB in May 2014 for approval and published thereafter. The public consultation paper examines the three broad types of model for an aggregation mechanism: a physically centralised model; a logically centralised model; and the collection and aggregation by authorities themselves of raw data from TRs. Within these three broad types of model, a variety of detailed alternatives exist that would provide differing levels of sophistication of service.
These alternatives would need to be examined further in the final report in May and in any follow-on work that may be commissioned to take forward one of models following this feasibility study. i . The study is focusing on the feasibility of options for data aggregation in the current regulatory and technological environment and given the existing (and planned) global configuration and functionality of TRs. The aggregation options are being considered on the basis that they would complement, rather than replace, the existing operations of TRs and authorities’ existing direct access to TR data. The paper analyses the key factors and challenges associated with the three models, taking into account the range of needs of authorities for aggregated data across TRs and focusing on those considerations that are most relevant to the potential choice of model. It divides these considerations into two types: • legal considerations, including those relating to submission of data to the aggregation mechanism, access to the mechanism, and governance of the mechanism: and • data and technology considerations, including those related to data standardisation and harmonisation, data quality, information security, and other technological considerations. Based on this analysis, the paper proposes a set of criteria to be used in order to provide a common and systematic structure for the assessment of the options in the final report. The paper does not at this stage propose draft conclusions or recommendations for the final report. The FSB wishes to have feedback via this public consultation process on these considerations and criteria before proceeding to the assessment itself.
The feedback received will inform the further analysis by the FSB study group regarding the aggregation solutions, the constraints, and the methodology to be followed for the assessment. The FSB invites comments in particular on the following questions: 1. Does the analysis of the legal considerations for each option cover the key issues? Are there additional legal considerations - or possible approaches that would mitigate the considerations - that should be taken into account? 2. Does the analysis of the data and technology considerations cover the key issues? Are there additional data and technology considerations - or possible approaches that would mitigate those considerations - that should be taken into account? 3.
Is the list of criteria to assess the aggregation options appropriate? 4. Are there any other broad models than the three outlined in the report that should be considered? 5. The report discusses aggregation options from the point of view of the uses authorities have for aggregated TR data.
Are there also uses that the market or wider public would have for data from such an aggregation mechanism that should be taken into account? Responses should be sent by Friday 28 February 2014 to fsb@bis.org with “AFSG comment” in the e-mail title. Responses will be published on the FSB’s website unless respondents expressly request otherwise. ii . Table of Contents Page Executive Summary ................................................................................................................... 3 Introduction ................................................................................................................................ 3 Chapter 1 – Objectives, Scope and Approach ............................................................................ 5 1.1 Objective of the Study ................................................................................................
5 1.2 Scope of the Study...................................................................................................... 5 1.3 Aggregation Models Analysed ................................................................................... 5 1.4 Preparation of the Study .............................................................................................
8 1.5 Definition of Data Aggregation.................................................................................. 8 1.6 Assumptions ............................................................................................................... 9 Chapter 2 – Stocktake of Existing Trade Repositories ..............................................................
9 2.1 TR reporting implementation and current use of data................................................ 9 2.2 Available data fields and data gaps .......................................................................... 11 2.3 Data standards and format ........................................................................................
11 2.4 Legal and privacy issues .......................................................................................... 12 Chapter 3 – Authorities’ Requirements for Aggregated OTC Derivatives Data ..................... 12 3.1 3.1 Data Needs .........................................................................................................
12 3.2 Aggregation Minimum Prerequisites ....................................................................... 14 3.3 Further aggregation requirements ............................................................................ 17 Chapter 4 – Legal Considerations ............................................................................................
19 4.1 Types of existing legal obstacles to submit/collect data from local trade repositories into an aggregation mechanism ............................................................................................ 21 4.2 Legal challenges to access to TR data ...................................................................... 23 4.3 Legal considerations for the governance of the system ...........................................
24 Chapter 5 – Data & Technology Considerations ..................................................................... 29 5.1 The Impact of the Aggregation Option on Data and Technology ............................ 29 5.2 Data aggregation and reporting framework .............................................................
30 5.3 Data reporting ........................................................................................................... 30 5.4 Principles of data management to facilitate proper data aggregation ...................... 31 5.5 Principles of data management regarding the underlying data ................................
31 5.6 Principles of data management regarding the technological arrangements ............. 38 1 . Chapter 6 – Assessment of Data Aggregation Options ............................................................ 40 Chapter 7 – Concluding Assessment ........................................................................................ 42 Appendix 1: Feasibility study on approaches to aggregate OTC derivatives data .................. 43 Appendix 2: Summary of the outreach workshop ...................................................................
51 Appendix 3: Extract from the Access Report (Table 6.2) ....................................................... 62 Appendix 4: Data Elements ..................................................................................................... 65 Appendix 5: Glossary of Terms and Abbreviations ................................................................
67 Appendix 6: Members of Workshop ....................................................................................... 70 Appendix 7: List of References ............................................................................................... 73 2 .
Executive Summary This section will contain a summarised version of the entire report targeted for a quick and comprehensive read [to be added after consultation]. Introduction G20 Leaders agreed, as part of their commitments regarding OTC derivatives reforms, that all OTC derivatives contracts should be reported to trade repositories (TRs). The FSB was requested to assess whether implementation of these reforms is sufficient to improve transparency in the derivatives markets, mitigate systemic risk, and protect against market abuse. A good deal of progress has been made in establishing the TR infrastructure to support the commitment that all contracts be reported. Currently, multiple TRs operate, or are undergoing approval processes to do so, in a number of different jurisdictions. The requirements for trade reporting differ across jurisdictions.
The result is that TR data are fragmented across many locations, stored in a variety of formats, and subject to many different rules for authorities’ access. The data in these TRs will need to be aggregated in various ways if authorities are to obtain a comprehensive and accurate view of the global OTC derivatives markets and to meet the original financial stability objectives of the G20 in calling for comprehensive use of TRs. The FSB, CPSS and IOSCO have identified the need for further study of how to ensure that the data reported to TRs can be effectively used by authorities, including to identify and mitigate systemic risk, and in particular through enabling the availability of the data in aggregated form. The FSB set up a group - the Aggregation Feasibility Study Group (AFSG) to study the feasibility of several options to produce and share the types of global aggregated TR data that authorities need to fulfil their mandates and to monitor financial stability, taking into account legal and technical issues.
The FSB’s terms of reference for the study are attached as Appendix 1. This draft report takes as a starting point existing international guidance and recommendations relating to TRs, including those contained in the January 2012 CPSSIOSCO report on OTC derivatives data reporting and aggregation requirements (“Data Report”) and the August 2013 CPSS-IOSCO report on authorities’ access to TR data (“Access Report”). It has also made use of the semi-annual FSB progress reports on the implementation of OTC derivatives market reforms, including on the implementation of comprehensive trade reporting requirements. Structure of the Report The report is structured as follows. Chapter 1 lays down the objectives, scope and approach followed by the feasibility study. Chapter 2 makes a brief stock-take of the current status of TR implementation, including the current and planned global configuration of TRs, in order to provide background on the scale and scope of the aggregation challenges. 3 . Chapter 3 summarises the different types of requirements of authorities for aggregated OTC derivatives data, focusing in particular on the minimum pre-requisites for aggregation in order that the data are useable by authorities to fulfil their various mandates. Chapter 4 describes the legal and policy considerations, concerning submission of and access to data and governance of the aggregation mechanism, that are relevant to the choice of aggregation model. Chapter 5 discusses the data and technology considerations associated with meeting authorities’ requirements for aggregated data under the different choices of model. Chapter 6 presents the criteria for the assessment of the options derived from the discussion in Chapters 3, 4 and 5, and (to be drafted for the final version of the report following public consultation) the assessment of the pros and cons of the different aggregation options against those criteria. Chapter 7 (to be drafted for the final version of the report following the public consultation) will conclude with the overall recommendations of the study, as well as pointing to policy areas that might need further attention from the FSB, standard setters or jurisdictions, and areas where further study may be needed. This consultative draft report has been prepared by the AFSG and approved for publication by the FSB. The FSB invites comments on the analysis contained in this consultative report and in particular on the following points: 1. 2. 3. 4. 5. Does the analysis of the legal considerations for each option cover the key issues? Are there additional legal considerations - or possible approaches that would mitigate the considerations - that should be taken into account? Does the analysis of the data and technology considerations cover the key issues? Are there additional data and technology considerations - or possible approaches that would mitigate those considerations - that should be taken into account? Is the list of criteria to assess the aggregation options appropriate? Are there any other broad models than the three outlined in the report that should be considered? The report discusses aggregation options from the point of view of the uses authorities have for aggregated TR data. Are there also uses that the market or wider public would have for data from such an aggregation mechanism that should be taken into account? Responses should be sent by Friday 28 February 2014 to fsb@bis.org with “AFSG comment” in the e-mail title. Responses will be published on the FSB’s website unless respondents expressly request otherwise. The feedback received will be taken into account in the finalised version of the report, which will be provided to the FSB in May 2014 and subsequently published by the FSB. 4 .
1. Chapter 1 – Objectives, Scope and Approach 1.1 Objective of the Study The goal of this feasibility study is to set out and analyse the various broad options for aggregating TR data for use by authorities in effectively meeting their respective mandates. The FSB, in consultation with CPSS and IOSCO, will then make a decision on whether to initiate work to develop a global aggregation mechanism and, if so, according to which type of aggregation model and which additional policy actions may be needed to address obstacles. The report is structured so that the final version in May will provide the relevant information for senior policy-makers to be able to make the above decisions, and to inform both senior policy-makers and the public about the analysis supporting that information. 1.2 Scope of the Study For each option, the final version of the report will: • set out the key steps necessary to develop and implement the option, • review the associated legal and technical issues, and • provide a description of the strengths and weaknesses of the option, taking into account the types of aggregated data that authorities may require and the uses to which authorities might put the data. The study is intentionally high-level in approach, comparing the effectiveness of the broad types of options that could be used in meeting the G20 goal that authorities are able to have a global view of the OTC derivatives markets. It does not attempt to analyse the specific technological choices of hardware and software, or define the specific legal and governance requirements. At this early stage of the analysis of the options, with so many elements of the scope and scale of the exercise still undefined, it is not possible to estimate the costs of the different options. The report includes instead a qualitative analysis of the relative complexity of the different options.
More detailed work on such issues is expected to take place in any follow-on work that may be commissioned by policy-makers. 1.3 Aggregation Models Analysed The main options for aggregating TR data explored by this study are: Option 1. A physically centralised model of aggregation. This model would feature a central database where required transaction and (if needed and available) position and collateral data would be collected from TRs and stored on a regular basis.
The facility housing the database would provide services to report aggregated data to authorities, drawing on the stored underlying transaction, position and collateral details. In order to do so, the facility would perform functions such as data quality checks, removing duplications, and masking or anonymising data as needed. Reports and underlying data would be available to authorities as needed and permitted according to a separate database of individual authorities’ access rights. Option 2.
A logically centralised model of aggregation. This model would feature federated (physically decentralised) data collection and storage of the same types of data as in Option 1. It would not physically collect or store data from TRs (other than temporary local caching 5 . where necessary in the aggregation process). Instead it would rely on a central logical catalogue/index to identify the location of data resident in the TRs, which would assist individual authorities in obtaining data of interest to them. In this model, the underlying data would remain in local TR databases and be aggregated via logical centralisation by the aggregation mechanism, being retrieved on an “as needed” basis at the time the aggregation program is run. 1 Either Option 1 or Option 2 could be implemented with varying degrees of sophistication or service levels, ranging from basic delivery of data in response to each request to - at its most sophisticated – providing additional services beyond basic delivery of data, such as performing quality checks/removing duplications, masking/anonymising data according to the mandate/authorisation of the requester, and aggregating data. The less ambitious versions of Options 1 and 2 would be less complex to implement but would not deliver the full range of services and meet the full range of uses of data that authorities seek in order to meet their mandates.
The final version of this report in May will include an evaluation of the extent to which less ambitious versions of each option could meet the range of user requirements. Option 3. Collection of raw data from local TR databases by individual authorities that then aggregate the data themselves within their own systems. Under this option, there would be no central database or catalogue/index.
All the functions of access rights verification, quality checks, etc., would be performed by the requesting authority and the responding authorities or TRs on a case-by-case basis. Access would be granted based on the rules and legislation applicable to each individual TR. (Option 3 represents the current situation for authorities wishing to aggregate data.
As noted later in this report, truly global and comprehensive data aggregation is not possible under current arrangements as no individual authority or body has comprehensive access to all data in all TRs. Under Option 3, authorities could expand their cross-border access to data from current levels by concluding additional international agreements, but the absence of a centralised aggregation mechanism would seem to preclude the provision of some forms of aggregated data, notably anonymised counterparty-level data.) In this report, the term “aggregation model” is used to refer to any one of the three options above. The term “aggregation mechanism” refers to mechanisms modelled on Option 1 and Option 2 as described above. The table below summarises the division of roles under the different aggregation models in performing the main tasks involved in aggregation, and the accompanying diagram provides a visual representation. 1 Within Option 2, data normalisation and reconciliation can be performed at a centralised or at a decentralised level.
Such sub-options do not fundamentally impact the following analysis and discussion. 6 . Option 3: Collection of raw data from local TR databases by individual authorities that then aggregate the data themselves within their own systems Option 1: A physically centralised model of aggregation Option 2: A logically centralised model of aggregation Storage of data used in aggregation Aggregation mechanism TRs for underlying data Temporary storage in aggregation mechanism TRs Quality checks / removing duplication Aggregation mechanism Aggregation mechanism Receiving authorities Masking/anonymisi ng data if required Aggregation mechanism Aggregation mechanism TRs, or home authorities of TRs Data delivery to authorities Aggregation mechanism Aggregation mechanism TRs or home authorities of TRs 7 . 1.4 Preparation of the Study The design of the study, including the diverse expertise within the AFSG, public consultation on the draft report, publication of the final report, is intended to ensure that the policy-makers have the benefit of a wide range of input before deciding upon the next steps, including which option to pursue. In preparing the draft the AFSG has used a variety of sources, including: • a survey of authorities in FSB member jurisdictions to gather additional information on the OTC derivatives data currently reported to TRs and accessed by authorities, as well as the status of their data aggregation capabilities on both local and global levels; • a workshop to discuss technical and legal issues in relation to the implementation of the alternative options, bringing together members of the AFSG and experts in the data, IT and legal issues involved, from inside and outside the financial industry (see Appendix 2); • existing reports and studies (see full list of references in Appendix 6). 1.5 Definition of Data Aggregation This report uses the Data Report definition of data aggregation “as the organisation of data for a particular purpose, i.e., the compilation of data based on one or more criteria”. Data aggregation may or may not involve logical or mathematical operations such as summing, filtering and comparing. As noted in the Access Report, authorities (depending on their mandates) may require access to aggregated data: • at three levels of depth: 1. Transaction-level (data specific to uniquely identified market participants and transactions) 2. Position-level (gross or netted open positions specific to a uniquely identified participant or pair of participants) 3. Aggregate-level (summed data according to various categories, e.g. by product, maturity, currency, geographical region, type of counterparty, underlier, that are not specific to any uniquely identifiable participant or transaction) • according to a certain level of breadth (in terms of scope of participants and products/underliers) • and according to a certain level of identity (named versus anonymous). 2 An important distinction in terminology therefore exists between the terms “aggregated data” and “aggregate-level data”.
“Aggregated data” are data that have been collected together, but may or may not have been summed; the data could instead be available at transaction-level or position-level. This process of collecting the data together is referred to as “data aggregation”. 2 More detail on the concepts of depth, breadth and identity is available in the Access Report. 8 . “Aggregate-level” data, on the other hand, are data that have been summed according to a certain categorisation so that the data no longer refer to uniquely identifiable transactions. Different authorities (or the same authority at different times) will require access at different levels of depth, breadth and identity for different purposes. The aggregation mechanism will need to be flexible enough to provide authorities with the level of access that they require and are entitled to for these different purposes. Chapter 3 discusses these data needs and how they affect aggregation requirements in more detail. 1.6 Assumptions The study focuses on the feasibility of options for data aggregation in the current regulatory and technological environment and given the existing (and planned) global configuration of TRs. In particular, the study is based on the following assumptions: • that comprehensive reporting of OTC derivatives trades is achieved in the major jurisdictions, in accordance with the G20 commitment, • that TRs operate under their existing functionality and data collection practices, • that the aggregation option being considered would complement, rather than replace, the existing operations of TRs and authorities’ existing direct access to TR data. The study does not set out to propose changes to the data reported to TRs or the data held by TRs unless those changes are necessary or desirable to achieve aggregation.
However, where needed, the study highlights any regulatory or other actions that might be needed in order to enable an option to be implemented or to improve its effectiveness. It notes where relevant improvements in market practices or infrastructure (e.g. introduction of a global Unique Product Identifier (UPI) or Unique Transaction Identifier (UTI)) that would assist the aggregation process, and it recognises where relevant that the aggregation option chosen may have impacts on TRs, market participants, related data providers, authorities and other stakeholders. 2. Chapter 2 – Stocktake of Existing Trade Repositories 2.1 TR reporting implementation and current use of data As indicated in the FSB’s sixth progress report on the implementation of OTC derivatives market reforms, 3 22 TRs in 11 jurisdictions are, or have announced that they will be, operational.
It is not anticipated that TRs will be located in all jurisdictions but rather that regulatory frameworks will, in some instances, facilitate reporting of market participants’ transactions to foreign-domiciled TRs that are recognised, registered or licensed locally. At present, the practical availability of TRs is quite uneven among FSB member jurisdictions, with very few TRs authorised to operate in multiple jurisdictions and some jurisdictions requiring that domestic reporting be limited only to TRs run by domestic authorities or operators. In some jurisdictions, firms are only permitted to meet their reporting obligations 3 See FSB sixth progress report on implementation http://www.financialstabilityboard.org/publications/r_130902b.pdf. 9 of OTC derivatives market reforms: .
by reporting to TRs that have been appropriately authorised (or alternatively granted an exemption from being authorised) in the jurisdiction in which the TR is offering services. In these jurisdictions, therefore, participants cannot meet their reporting obligations until relevant TRs have been authorised, recognised, or granted an exemption from a registration or licensing regime. In any given jurisdiction, the number of local TRs eligible for reporting ranges from zero to 11, and overseas TRs from zero to eight. The pace of implementation of TR reporting shows some differences across jurisdictions. In several jurisdictions there is some form of phased implementation, whether by asset classes or by market participant categories (largest financial participants/below threshold, regulated/end user).
By end-2014, a significant number of jurisdictions will have mandatory TR reporting in place for all asset classes. Other jurisdictions are either expected to have mandatory TR reporting in place by 2015 or have not yet set a date for all asset classes. The scope of implementation presents some differences. For instance, while financial institutions are subject to reporting in all jurisdictions, in some jurisdictions non-financial institutions may not be subject to mandatory reporting or some thresholds may be in place.
In some jurisdictions, transactions have to be conducted and booked locally in order to be subject to reporting, while in other jurisdictions transactions conducted locally but not booked locally or not conducted locally but booked locally are also subject to reporting. In some jurisdictions two-sided reporting is required while other jurisdictions have opted for one-sided reporting. In all but one jurisdiction, 4 reporting has to be made to TRs, with reporting to authorities being only a fall-back option when there is no TR in place. The time limit for reporting may also vary across jurisdictions from reporting on the same day, up to T+30, with most jurisdictions applying a reporting limit under T+3. In most jurisdictions where TR reporting requirements are in place, authorities typically have access to the data held in the TRs as consistent with their mandates. However in some jurisdictions, only a subset of authorities has regulatory access based on the current regulation in place.
In other jurisdictions, where TR reporting requirements are not yet in place, access is provided on a voluntary basis. These differences reflect the different pace of TR legislation implementation across jurisdictions. Authorities usually receive the data based on a specific format according to their respective mandate (with the format differing across authorities) while in some jurisdictions authorities have continuous online access to TRs. Most authorities have access to data based on several mandates (such as financial stability assessment, micro-prudential supervision, and market conduct surveillance). Even once reporting requirements are in place in all jurisdictions, no single authority or body will have a truly global view of the OTC derivatives market, even on an anonymised or aggregate-level basis, unless a global aggregation mechanism is developed. 4 In that jurisdiction, reporting to either the TR or authorities is allowed. 10 .
2.2 Available data fields and data gaps The review of data collected by TRs demonstrates that there are strong commonalities on data fields collected across jurisdictions for a number of key economic terms of contracts such as start dates, description of the payment streams of each counterparty, value, option information needed to model value, and execution information such as execution venue name and type. However, some differences in approach remain, including (but not limited to): • the main difference relates to the market value of transactions and collateral or margining information that are mandated for reporting in some jurisdictions, while they are not in other jurisdictions, • the distinction between standardised and bespoke contracts is reported only in one jurisdiction, • execution information is widely reported except the information on whether a trade is price-forming, which is collected only in a few jurisdictions, • clearing information is not widely reported with the name of the CCP being collected only in a few jurisdictions. In some jurisdictions, transactions once cleared must be reported as being modified transactions, while in other jurisdictions, the clearing results in the required reporting of both the termination of the initial transaction and the initiation of new ones. While transaction, product and legal entity identifiers are widely used, it seems that transaction and product identifiers may depend on different taxonomies which would require further details to ensure unicity (for transaction identifiers) and to check for consistency (for product identifiers) before aggregation. 2.3 Data standards and format The review of data standards and formats utilised by the different TRs in collection and storage of OTC derivatives data demonstrated different approaches that were chosen by various jurisdictions and TRs in addressing the G20 reporting requirement implementation. When it comes to the development and maintenance of reporting data standards, different jurisdictions follow different approaches. While a number of jurisdictions provide specific layouts of the fields and files, some do it for all OTC derivatives asset classes while others have different treatment for different asset class products. On the other extreme, a number of jurisdictions have not implemented data standards for TR data at all.
In some cases, jurisdictions have chosen this approach intentionally by relying on relevant internationally accepted communication procedures and standards, while in other cases standards and harmonisation work is being undertaken but is not yet complete. In this context, some jurisdictions suggest the use of an UPI approach as a uniform product data standard for OTC derivatives data reporting in their rules. However, there is currently no internationally accepted UPI standard.
Among jurisdictions that have prescribed standards, they mostly cover credit, currency, equity and interest rate OTC derivatives although the coverage varies from jurisdiction to jurisdiction. Very few jurisdictions have developed data standards for commodity derivatives, particularly the identification of the underlier (and not only the derivative itself, for which the UPI may suffice). 11 . While some do standards development and maintenance on the regulatory level, others outsource that either to TRs or industry associations or similar body. Some authorities use a hybrid model of the above approaches. A number of authorities indicated that they use some proprietary data items such as Reference Entity Database (RED) Codes 5 in their reporting requirements. However, it was noted that the proprietary licensed data standards seem to be used only for reporting of credit derivatives. The application of tagging standards also varies significantly among jurisdictions yet, in general, only a minority of authorities decided to implement data tagging standards for the OTC derivatives reporting. 2.4 Legal and privacy issues As previously pointed out in the FSB progress reports on the implementation of OTC derivatives market reforms, some jurisdictions have privacy laws, blocking statues and other laws that might prevent firms from reporting counterparty information and foreign authorities from reaching the necessary data from TRs. Some of the jurisdictions will address the issues by changing/enacting new legislations, while others continue to work through possible solutions. In most jurisdictions, TRs are permitted to disclose confidential information only to entities that are specified in law or regulation, and generally these entities include only authorities.
In such cases, access to TR data may be provided to third country authorities only if certain conditions are met, including, for example, the conclusion of an international agreement or Memorandum of Understanding (MoU). In several jurisdictions, a local TR may directly transmit data only to national or local authorities. In some of these jurisdictions, foreign authorities may be granted indirect access to the data via national or local authorities, provided certain conditions are met, including, for example, MoUs between national/local and foreign authorities. 3. Chapter 3 – Authorities’ Requirements for Aggregated OTC Derivatives Data 3.1 3.1 Data Needs Both the Data Report and the Access Report broadly outline the potential data needs of authorities and provide guidance for minimum data reporting and access to TRs.
The Data Report also discusses the importance of legal entity identifiers and a product classification system and makes general recommendations on how to achieve adequate aggregation. The Access Report focuses on the access requirements of authorities under different mandates and the procedures that facilitate authorities’ access to TR data. In order to categorise the diverse needs of authorities for aggregated data across TRs, this feasibility study follows the functional approach employed in the Access Report. This approach maps data needs to individual mandates of an authority and their particular objective 5 Unique alphanumeric codes assigned to all reference entities and reference obligations, which are used to confirm trades on trade matching and clearing platforms. 12 .
rather than to a type of authority. These mandates may evolve over time. They include (but are not limited to): • Assessing systemic risk, • Performing general macro assessments, • Conducting market surveillance and enforcement, • Supervising market participants, • Regulating, supervising or overseeing trading venues and financial market infrastructures (FMIs), • Planning and conducting resolution activities, • Implementing currency and monetary policy, and lender of last resort, • Conducting research to support the above functions. Appendix 3 describes these mandates as defined in the Access Report. Each mandate has different data needs. The mandates differ considerably in their requirements for data aggregation.
For example, authorities conducting market surveillance and enforcement generally need only data from market participants and infrastructures in their legal jurisdiction. They are frequently also supervisors of the TR where their market participants report, potentially giving them greater access and control of data. In contrast, other mandates would require access to a certain depth and breadth of data across participants and underliers which would not lend itself to a narrow jurisdictional view.
For instance, authorities who assess systemic risk or perform general macro assessments have the need, according to the Access Report, not only for data on counterparties within their jurisdiction but also for anonymised data on counterparties outside their jurisdiction. These data are needed to assess global vulnerabilities and spill-overs between markets. Obtaining these data in a usable format requires the collection of data from many trade repositories in a consistent format with duplicates removed and identifying information masked, as described below.
It also requires the creation of aggregate-level data on exposures. Prudential supervisors similarly need data going beyond their market in order to assess the exposures of firms at a globally consolidated level. 6 For these mandates, a global aggregation solution is essential for providing adequate transparency to the official sector concerning the OTC derivatives market.
Currently, no authority has a complete overview of the risks in OTC derivatives markets or is able to examine the global network of OTC derivatives transactions in depth. The complex set of needs of various authorities calls for an aggregation mechanism providing flexibility and fitted for evolutionary requests as financial markets and products evolve. It is also equally important for such a mechanism to be evolutionary in nature in order to respond 6 Prudential supervisors would need the following aggregated data to assess the soundness of entities operating in multiple jurisdictions: Counterparty exposures to assess the counterparty credit risk; Data on net position, valuation and collateral to assess the market risk of each portfolio of OTC derivative instruments; Data on periodic contractual cash flows in OTC derivatives to be used for assessing overall liquidity risk of the entity. 13 . to evolving needs for aggregated data by authorities. It appears that a key factor differentiating these aggregated data relates to whether they refer to named data or not. To provide authorities with the aggregated data consistent with the Access Report, various types of data aggregation will be necessary to complement the data that authorities may directly access from TRs. Some of the most important processes that are essential for aggregating TR data are described in the following sections. 3.2 Aggregation Minimum Prerequisites The following steps are core to any aggregation of OTC derivatives data for all types of mandates. These steps would apply regardless of the aggregation model used.
Box 1 illustrates the various aggregation steps through some example uses of TR data by authorities with particular mandates. Chapter 5 further expands on technical implementation of these steps. a) User Requirements for Data Harmonisation TR data originate from a wide range of market participants submitting data in a variety of formats over numerous communications channels. TRs themselves have different interpretations of terminologies, reporting specifications and data formats depending on the rules in their jurisdictions and their own choices.
TR data must therefore be transformed into a common and consistent form for use in analysis on an aggregated level. This would be easier if the same interpretations and data standards are implemented across TRs. Where data standards and interpretations are different, harmonising the data is more difficult and perhaps in some cases impossible. Some important examples of necessary harmonisation are: • Need for a consistent interpretation of terminologies (e.g., transaction, position, UPI, whether the quantity of a transaction or of a position is expressed in the number of contracts or their value, etc.), • The standard and format for expressing the terms of a transaction (such as the transaction price, quantity, relevant dates, and terms specific to certain types of securities such as rates, coupons, haircuts, value of the underlying, etc.) and whether a transaction is a price-forming trade, • The identification of trades that are submitted for clearing and the child-trades created as a result.
In some jurisdictions transactions once cleared must be reported as being modified transactions, while in other jurisdictions, the clearing results in the required reporting of both the termination of the initial transaction and the initiation of the new ones (“alpha-beta-trade” issue). b) User Requirements for Concatenation Data necessary for fulfilling authorities’ mandates may be held in several individual TRs in different locations. This is the result of competitive forces as well as regulatory requirements in various jurisdictions. Data are, therefore, physically and logically fragmented.
The current landscape is described in Chapter 2. In order to analyse data, each authority will need, directly or indirectly, legal access and technical connections to each TR containing relevant data. Certain analyses can be 14 . accomplished with partially fragmented data sets. For example, the mandates “Registering and regulating market participants” and “Supervising market participants with respect to business conduct and compliance with regulatory requirements” can be accomplished with data only from the (potentially small) number of TRs where specific market participants report. In contrast, the mandate “Assessing systemic risk” requires data from essentially all TRs and therefore needs a great deal of concatenation. One challenge is how an authority can know which TR holds data relevant to its mandate, given the proliferation of TRs and the various reporting requirements in different jurisdictions. c) User Requirements for Data Cleaning In the numerous stages of data reporting and processing 7 from the origin of the trade, submission to the TR, aggregation, and up to the analysis by the authority, errors could be introduced in the data.
While TRs are required to produce clean data, it might still be necessary for the data to be checked for errors and corrected wherever possible before the aggregation mechanism is capable of delivering meaningful results. d) User Requirements for Removal of Duplicates An important issue inherent in OTC derivatives data is the problem of duplicate transaction records, or “double counting”. Duplicate records could potentially be collected and stored in several TRs. Duplicates might result from the concatenation of data from different TRs. Each party to a given contract might report the event (any “flow event” such as a new trade, an amendment, assignment, etc.) to two (or more) different TRs in the same or different jurisdictions.
For example, Party A might report an event to a TR located in jurisdiction A and Party B might report the same event to a TR located in jurisdiction B. If data from the TR A and the TR B are combined into a single dataset, a record for this single event will appear in the dataset twice. This double-reporting may have been done to comply with local regulations; alternatively, it may have resulted from voluntary reporting practices. For instance, when a transaction is made on an electronic trading venue with an associated TR, the transaction might automatically flow into the venue’s TR, but the counterparty might also choose to report it to another TR so that it can gain a comprehensive view of its transactions through that utility. It is challenging to eliminate duplicate transactions particularly when combining two different datasets, and even more so in the absence of data harmonisation and standardisation.
If the two datasets are simply concatenated, the combined dataset would include duplicate transactions and any measures of exposure or other sums would be biased. If a global system of UTIs were in place, these could be used to match and eliminate the duplicates. If there is no effective UTI, the authority then has the following options: • 7 If the dataset is named or partially anonymised, the analyst (or aggregation mechanism in Options 1 and 2) could develop an approach to eliminate likely duplicates assuming some accepted degree of error (for example, the user could Processing refers to all steps incurred by data along the trade lifecycle, including the amendments to the contract, that in some jurisdictions have to be reported to the TR and thus increase the probability of errors to be introduced in the data. 15 .
define duplicate events as those with the same counterparties, same contract terms, and same transaction date and times). • If the dataset is fully anonymised, i.e., no counterparty information is provided, there is no solution to remove the duplicates. e) User Requirements for Anonymisation Under certain mandates, authorities only have rights to obtain anonymised data and may be legally prevented from obtaining named data. Other mandates additionally necessarily require access to named data, at least for participants and/or underliers located in their respective jurisdictions. There are two ways to anonymise named transaction data: • Records can be fully anonymised, where the counterparty name or public identifier (such as Legal Entity Identifier (LEI)) is redacted. This type of anonymisation is simple and can be performed on different datasets of raw transaction events prior to concatenation.
For example, TR A and TR B can themselves remove counterparty names from their respective datasets before sending to a user third party to combine. It has to be highlighted that once raw transaction event data are fully anonymised, the derivation of position data or other summing by counterparty is not possible. Also it has to be emphasised that, as mentioned above, removing duplicates from fully anonymised data would be impossible. In particular, full anonymisation implies also the removal of UTIs from the data because they are based on codes that identify participants. • Alternatively, records can be partially anonymised, or masked, where counterparties are given unique identifiers that are used consistently across the entire dataset.
For example, TR A could assign the identifier “1234” to Market Participant X and “5678” to Market Participant Y. Partial anonymisation could be performed by a single party, i.e., the aggregation mechanism, to perform the masking on a given dataset. In this case, if TR B assigns the identifier “ABCD” to Market Participant X, a user third party could not know it is the same entity as “1234”.
Partial anonymisation could also be performed locally in TRs, based on a set of agreed-upon and consistent anonymisation rules and translation data. Partial anonymisation allows a user to construct positions or otherwise sum up raw events by unique counterparty, without knowing the actual identity of that counterparty. This is crucial for many types of network and systemic analysis as well as for netting gross bilateral positions. While partial anonymisation is an appropriate step for providing authorities with some needed aggregated data, it remains that some mandates additionally necessarily require named aggregated data. The above approaches are possible assuming that the dataset is comprised of raw transaction event data.
If transaction flow events are summed up into positions or otherwise aggregated, it is impossible to eliminate double counting because the building blocks going into each position calculation are not known. f) User Requirements for Providing Timely Data Authorities have a need for both regular requests and ad hoc requests. Routine requests would typically come at daily, monthly or quarterly intervals (or other pre-defined regular intervals). In some cases, rapid responses to ad hoc requests will be essential, in particular under stress 16 . conditions. In general, the data should be available within a short time lag. While in some cases almost real time data is necessary, a timeliness of up to three business days (T+3), which happens to be the maximal time lag for reporting in almost all jurisdictions, would be enough for most of the mandates. Because some jurisdictions do not require real-time reporting, aggregation exercises that require data from those jurisdictions can only be done at an appropriate delay after the event. Attempting aggregation earlier would lead to incorrect results. 3.3 Further aggregation requirements The following steps would be needed for certain types of analysis but are not essential for all mandates. a) User Requirements for Calculation of Positions Several mandates require information on the positions of market participants: the sum of the open transactions for a particular product and participant at a particular point in time. This will require tools to identify the transactions to be summed.
In particular: • The participant identifiers (LEI) are required to accumulate accurate position data across TRs. The LEI with hierarchy (for consolidation purpose) is also needed for some mandates at least in a second step when the fully fledged LEI is in place. • Product identifiers (ideally UPIs, and any other instrument identifier available) are needed to do accurate product-level analysis. Different analyses require different levels of product identification granularity. • ID of underlying (e.g.
reference entity identifier, reference obligation and restructuring information in case of credit derivatives, reference entity identifier for equity derivatives, benchmark rate in the case of interest rate swaps and cross currency swaps) are required to conduct various analyses (for instance, to measure total exposure in a given reference entity, or to value the trades for any analyses where market values, rather than notional amounts, are aggregated and where the TR does not collect those market values). b) User Requirements for Calculation of Exposures The current exposure of a derivative portfolio — defined as the cost of replacing the portfolio in current market conditions net of any collateral backing it — is an important measure of risk that is of interest to authorities. Calculating exposures requires not only position data, but also data on valuations, collateral (e.g., amount and composition of applied collateral) and netting sets. Such information includes external bilateral portfolios between pairs of market participants and portfolios of centrally cleared transactions (particularly important for including collateral information).
An ID of collateral pool and netting set would be necessary to connect multiple trades to their common collateral pool and netting sets. This data will not be available in all TRs due to differences in regulatory requirements. Any aggregation solution should, however, take into account the requirements to calculate exposures where possible and to incorporate more complete data in the future.
There is also a need for authorities to be able to calculate exposures combining aggregated OTC derivatives data with data on exchange-traded products or cash instruments (bonds, equities, etc.). 17 . Box 1: Illustrations of data aggregation requirements This box illustrates the various aggregation requirements described above through some example of data uses of by authorities with particular mandates. Other uses by authorities with different mandates frequently encounter several of these issues. Business conduct supervision. The first example relates to an authority with a mandate for supervising participants with respect to business conduct (see Annex 4 for data such an authority may have access to). This regulator suspects that a bank in its jurisdiction has traded on private information obtained during a loan renegotiation with a debtor by buying credit default swaps (CDS) that offer protection against potential losses due to the default of that debtor.
Hence, the regulator wants to know the net amount of credit protection on the debtor bought by the bank over the past few days. An aggregation mechanism would allow the authority to have a broader picture in order to detect violations. As the relevant CDS transaction event records may reside in a number of different TRs, they must first be brought together. Essentially these transaction records must be extracted from their respective TRs and concatenated.
This could be done easily if each TR used the same data fields (with the same meaning/interpretation) and formats. Two particularly important data fields in this application are those containing the identities of the bank counterparty and the debtor referenced in the CDS contracts. These could be accurately searched if all TRs used the universal set of unique LEIs.
8 As transaction events may have been reported to more than one TR, the regulator would want any duplicate records to be eliminated. If all TRs applied a UTI for each of the trades that they store, this could be done simply by eliminating any records from across TRs with duplicate UTIs. Armed with a comprehensive and comparable list of duplicate-free transaction event records, the regulator could finally compute the net credit protection bought by the bank on its debtor over the past few days. It should do this by summing purchases of credit protection and subtracting any sales of credit protection.
Only ‘price-forming’ trades should be included in this calculation. 9 Calculating positions. A second example of data uses illustrates the aggregation requirement of calculating positions.
It concerns a central bank with a financial stability mandate with a need to check whether any systemically-important firms in its jurisdiction have large OTC derivatives positions. Suppose that such authority wanted to know the size of CDS positions referencing a particular country’s sovereign debt sold by Bank A (including all its subsidiaries), located in its jurisdiction. The transaction records that comprise this position potentially reside in a number of different TRs, so the authority would need the relevant trade records to be extracted and concatenated as in the first example. In this case, relevant contracts are any that end up with Bank A as the protection seller.
This includes all contracts originally sold by Bank A but which have not yet matured or otherwise terminated. It also includes any contracts that 8 In addition, if the regulator asked authorities in other jurisdictions to search for any trades conducted by legal affiliates of the bank, it would be a simple matter to find their LEIs given the LEI of the bank once the hierarchy is in place within the LEI system. 9 Non-price-forming trades, such as those arising from compression cycles and central clearing, would not affect the bank’s positions against the potential default of the debtor. They only affect the counterparties to these positions. 18 .
were reassigned from the original seller of protection to Bank A. In both of these cases, the latest information about the trade contract would be needed, so any partial terminations or notional amount increases would also have to be extracted from the TR. After harmonising data standards and removing any duplicate transaction records, again as in the first example, the position of Bank A referencing that country’s sovereign debt could finally be computed as the sum of outstanding transaction event records. Expanding this second example brings in the aggregation requirement of anonymisation. Say the authority learned that Bank A had sold a large volume of credit protection on the sovereign debt of the country mentioned above. It might then want to know the overall degree to which market participants relied on Bank A for the supply of this insurance. Simple measures of market share require a comparison of the volume of protection sold by the bank with the overall level of protection sold by all market participants.
More advanced statistical measures of network centrality take into account not only that many counterparties might rely directly on Bank A for credit protection, but that others might rely indirectly on Bank A having bought protection from a counterparty that in turn bought protection from Bank A. Computation of such measures requires data on all such links between counterparties as summarised in a matrix of bilateral positions, but the names of the protection buyers and sellers (other than Bank A) are not important. Hence, the names of these market participants could be partially anonymised before centrality is calculated. Calculating exposures.
Finally, further expanding this example illustrates the aggregation requirement of calculating exposures. Say the authority was concerned about the solvency of a financial institution in its jurisdiction and, given the centrality of Bank A as a seller of an important type of credit protection, wanted to know if Bank A was exposed to this institution through OTC derivatives. Computation of this exposure first requires data on all outstanding positions across various OTC derivative asset classes between Bank A and the institution of concern (i.e.
named data is required). As in the first example, the positions can be calculated, after data harmonisation and removing duplicates, by summing all open transaction between Bank A and the other entity. Then it requires these positions to be valued.
Some TRs will collect this valuation information, but others will not. Where it is not collected, derivatives positions may be valued using the prices of their underlying assets, which may be taken from a third-party database. This could be facilitated by the use both by TRs and third-party price providers of standard codes to identify underlying assets. In principle, any collateral posted against the market value of a bilateral derivatives portfolio should then be deducted from that market value to determine the exposure. However, not all TRs will collect this information and third-party sources of collateral data are much less readily available than for price data. 4. Chapter 4 – Legal Considerations TRs are mostly regulated at the national level by national laws, and TRs that operate on a cross-border basis may be subject to more than one regulatory regime.
10 10 The TR may be regulated in a jurisdiction other than its home jurisdiction, due to being registered, licensed or otherwise recognised or authorised in that jurisdiction, or conditionally exempt from registration requirements in that jurisdiction. 19 . Rules applicable to TRs usually concern the fields and formats for the information being reported (mandatory reporting), information being accessed (regulatory access) and organisational requirements. TRs are also usually subject to professional secrecy requirements, including relevant confidentiality/privacy/data protection laws. The feasibility of Options 1, 2 and 3 in the current legal environment depends on the compatibility of the steps needed to implement these different options with the existing rules applicable to TRs. Legal challenges in implementing the different options stem from different levels of applicable law within a jurisdiction (e.g. sectoral legislation and/or confidentiality law of general application) as well as from cross-border issues. This chapter analyses the legal considerations associated with the feasibility of the aggregation options described in Chapter 1 following three main dimensions: (i) the submission of the data to the global aggregation mechanism, (ii) access to the global aggregation mechanism, and (iii) the governance of the global aggregation mechanism.
For each component, the chapter presents legal considerations associated with the implementation of each option. The analysis focuses on the jurisdictions where TRs are established/registered/licensed 11, or will be in the short term, and pertains to the legal considerations applicable to data reported to TRs on a mandatory basis. 12 Last but not least, the analysis focuses on the feasibility of aggregating data held in TRs that are not “personal data” (i.e., data on natural persons 13). In the exceptional cases where personal data are stored in TRs, this study assumes that personal data would not be included in the aggregation mechanism because it would likely not be needed in order to satisfy authorities’ data requirements. Besides the reference material mentioned in Chapter 1, the analysis of this chapter has also been informed by the FSB fifth and sixth progress reports on the implementation of OTC derivatives reforms 14 which include descriptions of confidentiality issues related to the reporting of OTC derivatives into TRs.
The analysis also builds upon the discussion of the International Data Hub relating to global systemically important banks (G-SIBs) and the LEI global initiative. 11 Appendix D of the FSB’s sixth progress report on implementation of OTC derivatives reforms provides a list of TRs operating or expected to operate as of August 2013. The list of jurisdictions includes: Brazil, Canada, European Union, Hong Kong, India, Indonesia, Japan, Russia, Singapore and the United States. 12 There are two kinds of data reporting: mandatory reporting and voluntary reporting. The former is required by legislations and regulations, while the latter is reported without such requirements.
The ability to share data reported to TRs on a voluntary basis raises different legal issues which are out of scope of this study. 13 Personal data could be data about natural person counterparty to the trade, or data about a natural person that arranged the trade on behalf of counterparty. 14 http://www.financialstabilityboard.org/publications/r_130415.pdf http://www.financialstabilityboard.org/publications/r_130902b.pdf 20 . 4.1 Types of existing legal obstacles to submit/collect data from local trade repositories into an aggregation mechanism 4.1.1 Legal requirements applying specifically to the TR seeking to transmit data to the aggregation mechanism and regulating its capacity to share data In the existing regulatory environment, a TR seeking to transmit information to an aggregation mechanism – either to a physically centralised aggregation mechanism (Option 1) or a federated aggregation mechanism (Option 2) may face legal obstacles in its home jurisdiction, or in other jurisdictions in which the TR is regulated. In most jurisdictions legal requirements applying to TRs include limitations on the types of entities with which the TR may share data. These legal requirements may prevent local TRs from transmitting confidential information to an aggregation mechanism, depending on which entity operates the central aggregator, and which authorities have access to the aggregation mechanism. In several jurisdictions, TRs may transmit data only to national authorities, which would prevent the local TR from submitting data directly to an aggregation mechanism located outside the home jurisdiction. 15 In other jurisdictions, a local TR may share data with specified entities, or with entities of a specified kind (e.g., public entities such as authorities or regulators, and not private entities). In most jurisdictions, TRs are not permitted to disclose any confidential information to any person or entity other than authorities expressly authorised.
In some jurisdictions, the list of entities with access to TR data is defined by law 16. In others, the TRs’ supervisors may be authorised to designate the third-country entities entitled to access data held in local TRs. 17 In this context, the implementation of Option 1 and Option 2 (other than temporary local caching where necessary in the aggregation process), would require explicitly prescribing the aggregation mechanism (by law or by regulation) among the entities entitled to accessing local TR data.
This approach would require amending existing laws and/or regulation in several jurisdictions. In some jurisdictions, legal requirements include limitations on the purposes for which the local TR may share data with each type of entity. For example, some laws may restrict a local TR from sharing data with an entity that is a prudential regulator unless the data is required by the regulator for prudential supervision purposes. Unless it is possible under current law or regulation to designate or to include the aggregation mechanism as an entity entitled to access the data to the extent that the aggregation mechanism is fulfilling its mandate, TRs in such jurisdictions would not be allowed to share confidential information with the aggregation mechanism absent a change in law or regulation. Under Options 1 and 2, if the transmission of data from the individual TRs to the aggregation mechanism is performed on a routine basis, the TR may not know at the point of transmission which authorities will seek to access the data or for what purposes, and the TR therefore could 15 Brazil, India, Russia, Turkey 16 European Union 17 United States 21 .
not directly apply any access controls at its end. Where TRs are legally required to control access, they would be reliant on the aggregation mechanism to do so on their behalf. This outsourcing of controls might not be allowed in some jurisdictions without a change in law or regulation. If so, the issue would have to be addressed by the governance framework establishing the aggregation mechanism and regulating its access.
The governance issue including access rules is further discussed in Section 4.3. 4.1.2 Legal requirements of general application Privacy law, blocking statute and other laws A local TR may also be subject to legal requirements of general application such as privacy laws, data protection laws, blocking/secrecy laws and confidentiality requirements in the relevant jurisdiction, which are applicable to all the options. These legal requirements may prevent the TR from transmitting certain types of information to an aggregation mechanism under Options 1 and 2 absent a change in law or regulation. The legal requirements of general application that may prevent a TR or authority from transmitting data to the aggregation mechanism under Options 1 and 2, and may in some cases mirror obstacles that prevent participants from submitting data to a TR in the first instance. Those obstacles are discussed in the FSB’s fifth and sixth progress reports on OTC derivatives market reform implementation 18.
For example: • privacy laws may (subject to exceptions) prevent a TR from transmitting counterparty information to the central database (wherever located) where that information identifies a natural person or entity; • blocking/secrecy laws may (subject to exceptions) prevent a TR from transmitting/disclosing information relating to entities within a particular jurisdiction, to third parties outside that jurisdiction and/or foreign governments. In some jurisdictions, the TR may be able to rely on exceptions to privacy laws expressly listed in the laws or where there is a counterparty’s express written consent to the disclosure of the data. However, the requirements for consent differ across jurisdictions. In certain jurisdictions, one-time counterparty consent to disclosure to a TR is sufficient, while in others counterparty consent may be required on a per-transaction basis Consequences of breach As noted, the source of the above legal requirements may be laws, regulations or rules of the jurisdiction in which the TR is located, or of another jurisdiction in which the TR is regulated. Other sources of these requirements may be conditions of the TR’s registration, licensing or other authorisation in a particular jurisdiction, or contractual arrangements to which the TR is a party, including the TR’s own rules and procedures.
These conditions or contractual arrangements may be designed to support compliance with local laws, e.g., privacy laws. A TR that breaches these legal requirements may be exposed to civil liability or criminal sanctions in the relevant jurisdiction. Further, if a TR is required to ensure that the entity that operates the aggregation mechanism, or authorities that have access to the aggregation 18 See section 3.2.1. http://www.financialstabilityboard.org/publications/r_130415.pdf http://www.financialstabilityboard.org/publications/r_130902b.pdf. 22 and 6.3.1 of . mechanism comply with specified requirements (e.g. undertakings as to confidentiality) with respect to the data transmitted, the TR may be exposed to liability if the aggregation mechanism or authority breaches those requirements. These potential obstacles could limit the capacity of the TR to transmit confidential data to the aggregation mechanism, and could therefore limit the range of data held in the aggregation mechanism, which might prevent authorities from accessing all the information they need in carrying out their regulatory mandates. Factors mitigating the legal obstacles to transmission of data by TRs • Type of data being transferred: anonymised and aggregate-level data. The legal obstacles may differ depending on the type of data being transferred to the aggregation mechanism under Options 1 and 2. Sending aggregate-level data or data in anonymised 19 form could mitigate most of the confidentiality issues identified above which apply to the transmission of confidential data. On the other hand, it should be noted that transmission of data that has already been anonymised (e.g., with no LEI or other partyrelated information) or that has already been summed faces serious drawbacks, such as the inability to eliminate double-counting and the inability to perform calculations of positions or exposures as discussed in Chapter 3. • Authorities acting as intermediaries for the transmission of data into the database. Transmitting data from local TRs to the aggregation mechanism via authorities may alleviate some of the legal concerns identified above, since most authorities have, unlike TRs, the capacity to share confidential information with other authorities, provided certain conditions are fulfilled, notably within existing frameworks of cooperation arrangements for data sharing. 4.2 Legal challenges to access to TR data In a few jurisdictions, direct access by foreign authorities to data held in local TRs is not permitted.
However, in some jurisdictions 20, foreign authorities may be granted indirect access to the data via national authorities – usually the supervisor of the local TR (or after approval of the supervisor) – provided MoUs have been concluded. In most jurisdictions, regulatory access to TR data is provided by law and includes access by third country authorities, provided certain conditions are met. These conditions may include the conclusion of MoUs - or specific types of international agreements 21 - between relevant authorities on data sharing. 19 A methodology to do so would need to be further defined and demonstrated. Different types of anonymisation are described in Chapter 3.
The methodology would need to address the issue that, in some circumstances, anonymised counterparty identities may be ascertainable e.g. based on historical trading patterns or account profiles, or because of lack of depth in the market. 20 Brazil, Russia, and Turkey 21 For example, in the EU, as a condition for direct access to EU-regulated TR data by third country authorities from jurisdictions where TRs are established, the European Market Infrastructure Regulation (EMIR) requires that international agreements and co-operation arrangements that meet the requirements of EMIR be in place between the third country and the EU. For third country authorities from jurisdictions where no TR is established, EMIR requires the conclusion of cooperation arrangements. 23 .
In some jurisdictions, pre-conditions to access by certain authorities have to be met. For example, a TR may be required to take specified steps before sharing information with an entity, such as ensuring that an agreement or undertaking as to confidentiality, or indemnification 22 in respect of potential litigation, is in place with the requesting entity. Under Options 1 and 2, authorities would access global OTC derivatives data via the aggregation mechanism. New rules specifying who may access the data, the coverage of the information that may be accessed, and the conditions for access would therefore need to be globally agreed as developed in the governance section below. These rules and conditions for access would need to reflect any legal conditions under which the data was transmitted to the aggregation mechanism.
This new international framework may solve the existing access issues above to some extent in a sense that this framework can be a substitute for bilateral MoUs. 23 Under Option 3, authorities would access information directly at local TRs. Option 3 would depend on the completion of the additional steps required under the existing regulatory frameworks to permit access to local TRs by worldwide authorities or would require changes in the existing regulatory frameworks. 4.3 Legal considerations for the governance of the system 4.3.1 General analysis The objective of this section is to analyse the legal considerations related to the governance of the aggregation mechanism for each option proposed, analysing what would likely need to be defined and agreed internationally to ensure the global aggregation mechanism could be implemented and managed. Under Option 1, a physically centralised aggregation mechanism would be established to collect and store data from local TRs.
This aggregation mechanism would subsequently aggregate the information and provide it to relevant authorities as needed. Some changes to the existing regulatory frameworks would be required to set up an aggregation mechanism entitled to collect confidential information stored in local TRs. Option 2 would not physically collect or store data from TRs in advance of a data request, instead it would rely on a central logical catalogue/index to identify the location of data resident in the TRs. In this model, the underlying data would remain in local TR databases and be aggregated via logical centralisation by the aggregation mechanism, being retrieved on an “as needed” basis at the time the aggregation program is run. Options 1 and 2 require a global framework to be defined specifying (i) which entity would operate the aggregation mechanism, (ii) how the aggregation mechanism would be managed and overseen/supervised, (iii) access rules (which authorities would have access to which information according to their mandate and confidentiality restrictions in the use of data). 22 For example, in the US, the Dodd-Frank Act requires that, as a condition for obtaining data directly from a TR, domestic and foreign authorities agree in writing to indemnify a US-registered TR, and the SEC and CFTC, as applicable, for any expenses arising from litigation relating to the data provided.
The CFTC issued a final interpretive statement and the SEC issued proposed exceptive relief. 23 Other legal issues, e.g. indemnification issues, would still need to be solved. 24 . The framework for Option 1 would further require specifying the location of the physically centralised aggregation mechanism and the information to be collected and stored there. The framework for Option 2 would further require agreeing (i) which information would be incorporated into central logical catalogue/index for logical centralisation and access, (ii) how the federated aggregation mechanism would be operated. Option 3 would not require setting a global governance system but require the conclusion of international agreements (cooperation arrangements, memorandum of understanding, etc.) between relevant authorities and resolution of indemnification issues as mentioned in the previous sections. 4.3.2 The need for global governance frameworks under Options 1 and 2 Assuming an international commitment to set up an aggregation mechanism for OTC derivatives data, different possible governance approaches would permit the implementation of such a mechanism. Considerations for defining the supervisory/oversight framework entity running the database and the global Under Options 1 and 2, the global framework would likely need to define which entity operates the aggregation mechanism and in particular the nature of the entity that may run and manage the aggregation mechanism and how this entity could be supervised/overseen (if a private entity) or otherwise governed (if a purely public entity). At least two cases can be envisaged, depending on whether the database is run via a public-private partnership (cf. model of the LEI initiative) or if the central database is operated by a public entity (cf. model of the Data Hub). • Public-private partnership In the current landscape of TR services providers, the same global companies operate local TRs established in various jurisdictions, offering TRs services in line with each jurisdiction’s local requirements.
The existence of companies running different local TRs could pave the way to building a global infrastructure that would aggregate the information contained in local TRs on a not-for-profit basis and subject to public sector governance. In that regard, the LEI initiative provides an insightful example comprising a public-private initiative, leveraging the knowledge and experience of local infrastructures, with a global regulatory governance protecting public interest and open to all authorities worldwide. Several models could already be envisaged for the supervision/oversight of an aggregation mechanism on OTC derivatives data operated by a private entity. The private entity running the aggregation mechanism could be supervised/overseen by a college of authorities from different jurisdictions, which would set up a global supervision/oversight framework.
Another framework would rely on the direct supervision/oversight of the private entity by an international institution under a global governance framework. The global governance framework of the LEI initiative (which was set up in two years from the G20 mandate to the first operationalisation) is an example to consider, although aggregation of TR data is a more complex task than the generation of an LEI code. The key elements from the LEI initiative, which could be helpful in designing a global framework 25 . governing a TR data aggregation mechanism if run by a private entity, are summarised in Box 2. Box 2: Global LEI initiative G20 mandate to FSB (Cannes Summit, November 2011) The LEI initiative includes a four tiered system with a governing charter for the Regulatory Oversight Committee (ROC) 24, a Global LEI Foundation (GLEIF) as well as operation units such as the Central Operating Unit as well as the federated local operating units. 25 The LEI identification standard is provided by the International Organisation for standardisation (ISO) or more specifically ISO 17442, designed to ensure the unambiguous identification of the counterparties engaging in financial transactions. In this framework the ROC will take ultimate responsibility for ensuring the oversight of the Global LEI system, standards and policies. - ROC, established by Charter set out by the G20 and FSB. Members are authorities from across the world.
Responsibility for governance and oversight of the Global LEI system, and delivery of the broad public interest. The following are eligible to be a Member of the ROC: (1) any public sector authority and jurisdiction including regulatory and supervisory authorities and central banks; (2) public international financial institutions; and (3) international public sector standard setting, regulatory, supervisory, and central bank bodies and supranational authorities. - GLEIF, governed by independent Board of Directors (composed with balance between technical skills, sectoral experience, geographic balance). Upholds centrally agreed standards under a federated operating model. Will be established as a not-for-profit foundation in Switzerland.
Will operate central operating unit. FSB acts as a Founder of the foundation. - Local Operating Units. Build on local knowledge, expertise, and existing infrastructures. Operate to centrally agreed standards under the federated operating model. The FSB report, “A Global Legal Entity Identifier for Financial Markets”, highlights the creation, governance and function of a global LEI system. • Public entity An aggregation mechanism could also be run by a public entity.
Given the nature of the data that is collected based on mandatory reporting requirements, establishment of public entity might be less complicated from a legal perspective. The Data Hub on global systemically important banks (described in Box 3 below) has been recently established by the BIS through the conclusion of a Multilateral Memorandum of Understanding. The legal framework applicable to the Data Hub is a useful starting point for considering the implementation of Options 1 and 2, in the sense that the hub centrally collects global financial 24 http://www.leiroc.org/publications/gls/roc_20121105.pdf 25 See FSB report - http://www.financialstabilityboard.org/publications/r_120608.pdf 26 . data, including confidential data, and is able to share this information with relevant authorities. A similar governance framework could be envisaged for an aggregation mechanism comprising a public entity operating the infrastructure and the establishment of an international Governance Group. While the Data Hub is designed to be a connector among regulators, the aggregation mechanism being discussed in this report could be directly connected to TRs, albeit under regulatory oversight. Box 3: The International Data Hub As part of wider G20 initiatives to improve data to support financial stability, the FSB has developed an international framework that supports improved collection and sharing of information on linkages between global systemically important financial institutions and their exposures to sectors and national markets 26. The objective is to provide authorities with a clearer view of global financial networks and assist them in their supervisory and macro-prudential responsibilities. The key components of the governance of this initiative are the following: - Harmonised collection of data: common data templates for global systemically important banks have been developed under the FSB leadership to ensure consistency in the information collected. - Central hub: The International Data Hub has been set up 27 and centrally holds the data collected.
The data hub is hosted by the Bank for International Settlements (BIS). A multilateral memorandum of understanding (Multilateral Framework) establishes the arrangements for the collection and sharing of information through the Hub. Currently, the Framework is signed by banking supervisory authorities and central banks from ten jurisdictions.
Access of these jurisdictions to confidential information is contingent on the reciprocal provision and restricted to specific purposes such as supervisory activities. - GSIBs data is collected by their respective home authorities (data providers) and then passed on to the Data Hub. Data providers use their best efforts to ensure the quality of the data transmitted to the Hub. The Data Hub prepares and distributes standard reports to participating authorities (data receivers) on a regular basis.
In addition, data receivers can require additional information from the Hub, which fulfils the request after obtaining written consent from data providers. - Hub Governance Group: Participating authorities established a Hub Governance Group (HGG) to oversee the pooling and sharing of information. The HGG is responsible for all governance aspects of the multilateral arrangement. Considerations for the submission of data to the aggregation mechanism and addressing confidentiality issues The global governance framework would likely need to define how the aggregation mechanism collects data from local TRs. Two cases could be envisaged at this stage. 26 See recommendations 8 and 9 of the Report to the G20 Finance Ministers and Governors on “The Financial Crisis and Information Gaps” from November 2009, available at http://www.financialstabilityboard.org/publications/r_091029.pdf. 27 The Hub operations started in March 2013 with the collection of weekly data on the G-SIBs’ 50 largest exposures and quarterly data on aggregated claims to sectors and countries. 27 .
Firstly, the aggregation mechanism framework could be built on a global agreement mandating local TRs to submit relevant data (to be agreed on, which might or might not include confidential information) to the aggregation mechanism – and, where needed, changes to regulatory frameworks enabling the implementation of mandatory reporting to an aggregation mechanism. Requiring by law for the local TRs to report to the aggregation mechanism with the conclusion of a Multilateral Memorandum of Understanding for cooperation among relevant authorities would address, in most jurisdictions, the confidentiality obstacles identified above. This would however require a change in law in most jurisdictions. Secondly, the aggregation mechanism framework could be built with information flowing via national authorities. This is the approach followed for the Data Hub: national authorities transmit data (including confidential information) on G-SIBs to the central hub, which is entitled to centrally hold and share confidential information with relevant authorities participating in the framework.
28 As for the Data Hub, the protection of confidential data would have to be addressed via the conclusion of Multilateral Memorandum of Understanding. Strict confidentiality rules applying to the aggregation mechanism may also need to be defined. Laws applicable and confidentiality requirements in the jurisdiction where the aggregation mechanism resides and where data are stored either permanently under Option 1 or temporarily under Option 2 will be key components of the framework. 4.3.3 Considerations on access rules Under Options 1 and 2, authorities would access global OTC derivatives data directly at the aggregation mechanism. The global governance framework would therefore need to define rules on access to the information held at the central aggregation mechanism.
These rules may need to specify: • Who may access the aggregation mechanism (list of relevant authorities, official international financial institutions 29, etc.). • Scope of data access: The aggregation mechanism would provide authorities with a level of access in line with the principles defined in the Access Report. • Permitted use of data: the permitted uses for financial stability purposes and other relevant mandates would need to be defined, as would protection of confidential information that is accessed and consequences of any breach. • Modalities of access (direct vs indirect access, standard vs ad hoc requests). Under Option 3, individual authorities directly collect the raw data they need from local TR databases and then aggregate the information themselves within their own systems. This option can be implemented in the existing legal frameworks, if each relevant individual authority has access to the information it needs in all relevant local TR databases. 28 However, given the volume of data at stake for OTC derivatives, an automated process enabling national authorities to forward the relevant data to the database would be required. 29 In the Access Report, the IMF, the World Bank and the BIS are stated as official IFIs that foster and support financial stability through general macro assessments of global OTC derivatives markets, sectors or specific countries. 28 . The implementation of this option would therefore require solving the existing legal obstacles relevant to access to data (described in the previous section) in order to ensure that the legal frameworks applicable to local TRs in each jurisdiction allows access to TR data by third country relevant authorities: • granting access to third country authorities in the few jurisdictions where foreign authorities are not entitled to access TR data, • addressing the indemnification issues in jurisdictions where access to TRs data by foreign authorities is conditional to the conclusion of indemnity clauses, • concluding the necessary Memorandum of Understanding or other type of international agreements. It should be noted that, under Option 3, TRs as gatekeeper may interpret conservatively the minimum requirements for access set in the Access Report. This could lead to arbitrary decisions regarding the evaluation of mandates as well as what kind of data should be shared for each mandate. 5. Chapter 5 – Data & Technology Considerations As the implementation of data reporting to TRs gathers momentum, the development of technical and data solutions for data collection and aggregation has been largely at the local level. With local implementation advancing, it has become clear that different jurisdictions have implemented different solutions in the areas of technology choices or data standards and formats due to a number of factors: (i) local practices of infrastructures or market participants; (ii) jurisdictional-specific regulatory regimes; or (iii) the physical distribution of data over many different geographical locations which is in itself a significant factor, regardless of the progress made on standards, formats and other data and technology practices. In addition, there are potential data duplication issues resulting from counterparties reporting to multiple jurisdictions and TRs because of a combination of regulatory and other reasons. This chapter discusses the data and technology considerations associated with meeting authorities’ requirements for aggregated data under different choices of model. • to avoid the double-counting of transactions through the aggregation process.
This strengthens the case for the introduction of a global standard for identifying transactions uniquely. Lastly, this chapter reviews core technology considerations for availability and business continuity. 5.1 The Impact of the Aggregation Option on Data and Technology The requirements for data standards and the specification of technology to support aggregation do not drive the choice of aggregation model. The development of global standards for derivatives data and their aggregation is a foundational requirement under any data aggregation model. Standards form the basis for the interoperability of derivatives data; they are agnostic to choice of aggregation option as they are a prerequisite for every option. 29 . Indeed, the choice of aggregation option drives some key technological requirements. In this respect, it may be useful to think of the three options in terms of a nested set of technology requirements – there are some requirements that all three Options have, some requirements that Options 1 and 2 have but not Option 3, and some requirements that Option 1 has but not Options 2 and 3. In particular: • All three Options require a clear definition of the data so that there is unambiguous shared meaning among all parties, involving common data standards and understanding of business rules, so as to allow the collection of data for aggregation purposes. • In addition to these data standards requirements, both Option 1 and Options 2 require a shared catalogue to identify where data resides. • In addition to these data standards and cataloguing requirements, Option 1 adds a requirement for storage of data collected from TRs on behalf of the authorities. Because many of the data and technology factors apply independently of the final selection of aggregation option, this chapter addresses these factors more generally in terms of best practices in data and technology management. 5.2 Data aggregation and reporting framework In any data reporting or aggregations framework, data is accessed through a request (ad hoc or pre-defined) submitted to the system. The system performs the following functions: • verifies the identity and access rights of the data requestor; • analyses the request according to the data scheme, syntax and semantics; • controls its consistency and integrity; • optimises it for the purpose of execution; • executes the request according to storage scheme and access methods; • provides the results to the requester; • checks the performance of the aggregation mechanism and network performance (e.g.
response times, latency, traffic bursts). In the case of data aggregation framework of TR-based data access, the complexity of servicing a request for execution increases since the data might be stored in different physical locations, subject to different access rights, subject to different data standards and technology solutions, with possibly different access right methods and storage schemes. Regardless of the chosen system of data aggregation and regardless of its physical implementation, the general form of a request has to be defined as well as the protocol for analysing and interpreting it to allow meaningless aggregation of the data. 5.3 Data reporting In many jurisdictions reporting requirements oblige TRs to provide a specific set of data elements to regulators. At the time of this report, not all regulators and legislators have provided specific instructions as to the format and content of those the data elements they 30 . request but have rather left it at the economic definition level, leaving it to the discretion of the TRs to define those fields from a technical point of view. These differences and the absence of in standards and formats used have added complexity to the aggregation process at the jurisdiction and global levels. 5.4 Principles of data management to facilitate proper data aggregation Effective data management is a critical component of any data collection, reporting and aggregation framework. Accurate and useful data aggregation requires sound data management principles, including the following: • Regarding the underlying data: o o Standardisation, o • Integrity Availability and traceability. Regarding the technological arrangements: o Scalability, o Flexibility, o Business continuity, o Security. To evaluate the design and implementation methods of the OTC derivatives data aggregation approaches, each principle is described below. Technical implementation and best practices around each principle can vary depending on the aggregation approach. 5.5 Principles of data management regarding the underlying data 5.5.1 Data Integrity From the perspective of the data aggregation of trade reports, data integrity can be defined as ensuring that the processing involved in the aggregation: • Does not distort or misrepresent the data that was originally reported. • The result of the aggregation properly represents the underlying data without adding to or subtracting from them. Without integrity results could be inaccurate and inconsistent, thus creating questions about its authenticity and removing the ability of authorities to compare data from different sources or over time.
The concept of integrity also depends on the chosen aggregation model: under Option 1, the aggregation mechanism shall be designed so as to store and manage its data properly, while under the other options model integrity would mainly apply to consistent communication between entities. The principle of integrity must therefore remain flexible and be adapted to each particular model. 31 . Data quality Data integrity and data quality are related concepts. Data quality is the fitness of the data for its intended purpose. The single most important factor contributing to improved data quality is the adoption of standards that uniquely define and describe the data elements that comprise the components of financial instruments and transactions. Conformance to standards by market participants, TRs and authorities improves their ability to identify and remediate errors and discrepancies throughout the data supply chain. The discussion on data quality applies to all the aggregation models considered, with varying degrees of responsibility resting with the TRs, the aggregation mechanism and the individual authority. The following dimensions of data quality apply from individual data elements in a trade report to highly aggregated summaries of transactions and positions and should be considered in the analysis of the data aggregation approaches: • Completeness Missing or otherwise incomplete data for derivative products can render all other data about the products meaningless.
To ensure completeness of data for aggregation, the surest and most efficient way would have been for all TRs to collect and populate the same set of data elements. However, since such a unique TR data specification is not currently envisaged at an international level, a second best consists of ensuring that the data can be translated into a consistent standard. This still entails, though, significant constraints regarding specifications of the data stored by TRs. • Accuracy The values for a data element must conform to a standard definition and meaning to be accurate.
Likewise, the data elements collected by each TR should have unambiguous shared meaning and conform to standards for their content values in order for data aggregated across TRs to be accurate. Deviations from a standard definition and meaning for a data element might result in the uneven acceptance of valid values across TRs, degrading the quality of the data. However, when these deviations are small and the population is large, the data may still be considered ‘fit for purpose’ and may yield acceptable results when aggregated. • Timeliness In order to be timely, data must be available when and where needed, and provide the most current content.
However, aggregation across TRs is challenged by the collection mandates and reporting calendars of global authorities. This includes any differences in the requirements for the frequency and location of data access by authorities and the frequency and location for data collection from market participants. Since OTC derivatives contracts are often active over long periods of time the standards for maintaining and refreshing data have to be determined and harmonised across TRs and jurisdictions. Depending on the chosen scenario, the responsibility for updating data should be clarified, whether relying on TRs or on the global aggregation mechanism since this could hinder consistent aggregation. 32 .
• Consistency Data must have unambiguous shared meaning, allowable values, and business rules for their creation, maintenance, and retirement among the TRs. Without consistency, the quality of data across TRs will vary and negatively affect the ability to rely on the results of aggregation of transactions and positions. The agreement and setting of standards for TR data is a necessary condition to achieve consistency. • Accessibility To be accessible, collected data must be available to authorities where and when needed. Accessibility for aggregation is dependent on both technology capability and the legal agreement that grants authorities access to the data. Technology capability includes the data security systems and controls that govern permission to access data and the agreement among authorities on the TR governance process. • Duplication This dimension, often referred to as ‘Uniqueness’, is critically important to the prevention of double-counting of transactions and positions across TRs.
The development of standards for unique entity, instrument, and transaction identifiers provides the foundation for the prevention of duplication. As described in Chapter 3, avoidance of duplication is necessary for the purpose of aggregation. Standards for data content are in turn necessary to provide the capability to identify, correct, and prevent data duplication both within and among TRs. Operational factors contributing to high quality TR data Data quality must be addressed from that moment the data arrive at the TR and at every point where data are exchanged.
Both technical and business data quality practices must be applied to ensure the interoperability of the data among market participants, TRs, and authorities. The following operational aspects of data quality may need to be considered to facilitate proper data aggregation: • Whether the data are technically capable of being processed by the receiver and contain meaningful values. • Whether validation can be performed on the data to ensure consistency and completeness, and to avoid duplication. • Whether there are further checks for accuracy that could or should be carried out seeking to ensure that the reported items are correct. • Whether data quality is being managed proactively or reactively. • Whether and what combination of technical and business data quality checks are undertaken. While individual TRs will carry out validation of the data that is reported to them it is important that various TRs operationalise data quality processes in a consistent way 30. Thus the discussion here is about the data quality issues that are pertinent to integration of data 30 It is assumed that ensuring that the reports submitted to the trade repositories meet quality standards is outside the scope of any central aggregation solution. This role will be performed variously by the trade repositories themselves and the supervisors of the trade repositories and reporting entities according to the rules prevailing in a specific jurisdiction. 33 .
from several TRs for aggregation rather than data quality from the point of view of a single TR. A variety of technical checks would need to be conducted including checks for conformance to standards, format, allowable values, and internal consistency. Such checks would require some sort of a data dictionary and validation rules that define the allowable formats and values of the individual items or groups of items. This implies that an agreed-upon set of definitions and meanings of the data by industry participants, TRs, and authorities is essential, regardless of the aggregation mechanism. Some of these checks would also require access to reference data, such as those for counterparty and product identifiers as well as elements like country and state codes, including having a robust reference data management function. 5.5.2 Data standardisation Data standardisation is a necessary tool for effective high quality aggregation under each OTC derivatives data aggregation approach, although methods to achieve it may vary according to the particular approach.
It would be critical to determine which of the data being reported to TRs needs to be collected, reported and stored in a sufficiently consistent and standardised form so that the data can be easily and accurately aggregated for the regulatory purposes described elsewhere in this report for either aggregation model 31. Data standardisation also must address the potential need in some cases for authorities in their financial stability analysis to combine and aggregate OTC derivatives data with other data, such as data gathered from other sources, on other trades (e.g. exchange-traded derivatives, or cash market trades), and reference data, particularly defining the products traded and identifiers for their underlying instruments or entities. There are different approaches to standardisation which may achieve different levels of consistency. Achieving standardisation The most straightforward method for achieving standardisation is to implement consistent international standards for reporting of data to TRs and/or from TRs to authorities. Ahead of formal international standardisation, the public and private sectors can work together to agree on a common approach to be used as widely as possible.
In some jurisdictions, it might be possible to mandate the use of such an approach even if it is not an international standard. 32 The risk that different jurisdictions might endorse incompatible approaches makes it is highly desirable that the various authorities attempt to coordinate their approaches so that the necessary standardisation is achieved for the data aggregation mechanism. Such coordination would be valuable to all the aggregation models under consideration.
Alternatively, national authorities could identify common data requirements, and task TRs to cooperate internationally to identify a data standardisation approach that would be workable across TRs in achieving these requirements. 31 It is not intended to suggest that this means that the other reported data can be of lower quality, only that these are the key items necessary to make aggregation work. 32 For example, EU Regulation 1247/2012 allows for ESMA to endorse a standard product identifier to be used for EMIR trade reports. 34 . Standardisation can arise at two different points in the “data supply chain” and different aggregation approaches put emphasis on different points. • Upstream of each TR by elaborating common standards for reporting to TRs in the first place, • Downstream from TRs by using a translation mechanism to aggregate and share data originally provided in different formats. The translation could be carried out by the TRs before onwards transmission of the data, using a common TR data standard, or later in the processing. Note that “downstream aggregation” is complementary to “upstream aggregation” and that both might be necessary. Key OTC derivatives data elements requiring standardisation The following data elements have been identified in the Data Report as key to the aggregation process. • Counterparty identifier • Product identifier / product identification taxonomy • Transaction/trade identifier These are discussed in more detail below. Other data elements that have been identified as necessary or desirable to aggregate the data are: 33 • Identifier of the underlying of the derivative (cash market), • Timestamps of the execution, confirmation, settlement or clearing of a contract, • Types of master agreements. Counterparty identifier The counterparties to derivative transactions could be both legal persons and natural persons. The need for standardisation primarily applies to de jure and de facto legal persons. This report does not propose requiring standardisation of the identifiers for natural persons where alternative solutions will be employed. OTC derivatives data standardisation for legal persons needs to rely as much as possible on the LEI (see Box 2 in Chapter 4). Product identifier/ product identification system An international product classification system for OTC derivatives would provide a common basis for describing products, as described in the Data Report. Without a shared taxonomy the aggregation of data might be impossible or at best extremely difficult.
A standardised way of identifying the product traded will enable both the identification of situations where reports relating to the same product are made to multiple TRs, the identification of pockets of risk 33 This report assumes that data elements such as country codes and currency codes for which there are existing international standards that are well-used in other areas will also be used for the data under consideration here and so they are not discussed further. However, an affirmative use of these standards by the authorities in their guidance to the TRs could be very helpful. 35 . particularly in the areas of credit products and related instruments, and also enable comparisons of trading on related, but not identical, products. However, the standardisation of the depiction of financial products/instruments/contracts across markets and geographies has lagged behind the development of counterparty identifiers (i.e. the LEI). The requirements for product identification in order to achieve the objectives of data aggregation are: • An identifier that is sufficiently precise for the purposes of the authorities using the data, although recognizing that it may need to be supplemented by other data on the report. • An identifier that either explicitly or implicitly (through reference data) includes a well-articulated and precise classification hierarchy, so that data aggregation / analyses that does not require precise detail of the traded product are possible. • An identifier that is open-source, available to all users and has open redistribution rights. • A governance process for adding new values to the identification system, recognizing that new products will come into being over time. Authorities should have some role in the governance process. • An identifier that incorporates an approach that allows for historic data comparisons in a straightforward way, e.g. by not deleting or mapping old values.
The approach would maintain a version history of the identifiers. Several approaches have been put forward in the area of OTC derivatives product classification. These include approaches based on existing international standards (e.g. CFI Codes – ISO 10962 and ISO 20022 financial data standard) and industry-developed approaches (e.g.
from ISDA, the Financial Industry Business Ontology, algorithmic contract type unified standards). For the purposes of aggregation, either all jurisdictions should select the same approach or, if this cannot be achieved, then it should be possible to translate the approaches used at the reporting level into a common approach for integration, i.e. any integration process is likely to have to need a common approach even if the underlying reporting allows for more variation. Transaction/trade identification OTC derivative transactions may be reported to many different TRs and can, over their life, experience multiple amendments, notations and risk-mitigating exercises. If there is no standardisation, but instead different jurisdictions or different TRs use their own approaches, there could be problems in the areas of: (i) double counting if transactions are reported to different TRs; (ii) linking transactions when a life cycle event occurs and different events are reported to different TRs; and, (iii) difficulty in linking an original bilateral transaction to the resulting cleared transactions. Attempts to match up reports using other fields without some version of the UTI concept (such as the participants involved or the time of trade) are relatively complex and likely to be inefficient and inaccurate. 36 . Like the product identifier, the standardisation of transaction identifiers across markets and geographies has lagged behind the development of the LEI. While some jurisdictions have implemented authority-specific transaction identifiers, there is no global standard in place at the time of this report. There are also some jurisdictions that have no authority-specific transaction identifier. Data harmonisation In the absence of full data standardisation, reported data would need to be harmonised in order to ensure comparability. Harmonisation can bear different meanings depending on the chosen aggregation mechanism and the envisaged use of aggregated data.
Harmonisation is understood here as the process of adjusting differences and inconsistencies among different systems, methods or specifications in order to make the data derived from those systems mutually compatible. Harmonisation is required for fields where no standardisation has been agreed on. There are some proposals to develop a translation mechanism that will permit the aggregation of data originally provided in different formats. However, such a translation is not just a matter of format since the content of the data fields might also require translation.
Standardisation arrangements such as those discussed above apply to only certain key data elements. Harmonisation of fields would be critical under any option to achieve useful aggregation. While many vendors and technologists propose their own translation mechanisms or tools to aggregate data in disparate data stores and formats, such aggregation is prone to significant margins of error. While it might be helpful to provide initial leads for surveillance or enforcement activities such a technology is not a good substitute for standardisation of data to report the same data elements across the globe. Where complex datasets such as those dealing with OTC derivatives data are concerned, such methods could have higher rates of failure.
In addition, many of these also require investments to develop data dictionaries and intermediate translation standards in order to work. So, the costs of standardising data at the source may be well worth bearing, when set against the long-term benefits for decades to come. 5.5.3 Availability and traceability Data must be present and ready for immediate use and aggregation. There is an operational risk that the data will not be present and ready for use when needed for aggregation.
Market participants must deliver the data to TRs in time to allow the TRs to complete their processing cycle with final delivery or availability to authorities. Local and global authorities have different deadlines for reporting, holiday calendars, and operating hours. In the global context, there is no “end of day” for TRs, only specified times on a 24-hour clock by which data must be available to each authority served. In the case of Option 1, the availability of data at report/ aggregation time becomes the responsibility of the aggregation mechanism, even though in the longer run data also has to be available at the TRs.
Under Option 2, both the aggregation mechanism and the TRs have to be responsible for availability since both the catalogue/ index and the source data would be necessary to achieve desired results. Under Option 3, most of the responsibility for availability rests with the TRs. The ability to track the history of changes to content and location of data from their inception to disposal is the primary characteristic of traceability. When collecting data for the purposes 37 .
of aggregation, data quality is enhanced when the origin of data, the reasons for any changes, and those responsible for any changes to the data are known. While the primary responsibility for most of the changes to the data rests with the TRs, in case the aggregation mechanism makes changes to data such as anonymisation or masking, maintaining that audit trail would be the responsibility of the aggregation mechanism. 5.6 Principles of data management regarding the technological arrangements Solid technological underpinnings are critical for TRs to operate effectively in a secure, reliable, scalable and flexible manner to perform their functions effectively. The same considerations apply to data aggregation of TR data, albeit in a modified manner. To be able to evaluate each aggregation model, the principles of data management regarding the technological arrangement are discussed below. To be effective, a data collection, reporting and aggregation mechanism requires a technology environment that addresses the following: • Scalability, • Flexibility, • Business continuity, • Security. 5.6.1 Scalability Scalability is the ability of a system to continue operating at a required level of performance as the size or volume of data processed increases.
The system must be able to provide the same level of response time to queries whether the aggregation is for a single TR or across multiple TRs. As jurisdictions and TRs join in the global collection of derivatives data, the system must be able to grow to accommodate the increased volume of data collected, queries submitted, and reporting required. Beyond the collection and distribution of data, aggregation requires the raw processing power to perform calculations, respond to queries, and generate the reporting that is the reason for collecting the data. Under Options 1 and 2, the system must be able to service large numbers of simultaneous users on a global 365x24x7 basis.
Specifically under Option 1, there is a greater burden on securely receiving and storing large amounts of data. Under Option 2, and to some extent under Option 3, there is a greater burden on communications, multilateral data exchange, and the ability to locate data resident in distributed databases. 5.6.2 Flexibility Flexibility is the ability of a system to adapt to changes in requirements or processing demands. Aggregation requirements will vary based on the regulatory or supervisory mandates of the users of the system.
The system must be able to adapt to the diversity of requests and rapid evolution in queries as users become more sophisticated in their understanding of system capabilities and the data available. The system also requires the ability to adapt to new instruments, transactions, and the data storage they require. 38 . With experience, end-users will look at aggregation in different ways, with more complex queries, and demands for greater access to data. Flexibility impacts both Options 1 and 2 similarly, given that the aggregation mechanism has the responsibility to service the end-user regardless of the location of the source data. 5.6.3 Business continuity Business Continuity is “the capability of the organisation to continue delivery of products or services at acceptable predefined levels following a disruptive incident”. Business Continuity Management (BCM) is “the holistic management process that identifies potential threats to an organisation and the impacts to business operations those threats, if realised, might cause, and which provides a framework for building organisational resilience with the capability of an effective response that safeguards the interests of its key stakeholders, reputation, brand and value-creating activities.” 34 BCM needs to look beyond IT technical recovery capability and into a more comprehensive recovery of the business considering: (i) reputational risk; (ii) data supply chain (including TRs, connectivity, etc.); (iii) communications; (iv) sites and facilities; (v) people; (vi) finance; and (vii) end-users. The above should be considered against the changes to the environment in which the aggregation mechanism operates including political, economic, technological, social, legal, security, natural disasters, etc., taking into account crises and incidents that might disrupt the aggregation mechanism’s ability to deliver the services. The aggregation mechanism needs to exhibit network stability.
It should plan for both short-term service interruptions (generally caused by technical issues) and severe service interruptions (generally caused by larger events outside the control of the aggregation mechanism and jurisdictions). The latter might require the activation of an alternative site. Option 1 offers the possibility to manage the continuity of service in a single location, but emergency procedures (e.g. disaster recovery) need to be implemented in order to avoid single points of failure. Option 2 requires TRs to be always appropriately available in order to ensure required access. The case of unavailability of data in a single TR may produce inconsistencies and hamper the possibility of receiving complete information leading to incomplete or incorrect results. 5.6.4 Data security Data security is a comprehensive approach that includes the following: • Availability / Accessibility - information is available and usable when required, and the systems that provide it can appropriately resist attacks and recover from or prevent failures; • Confidentiality - information is observed by or disclosed to only those who have a right to know; • Integrity - information is complete, accurate and protected against unauthorised modification; 34 Source ISO22301:2012. 39 .
• Authenticity and non-repudiation - data source can be trusted. Achieving data security requires alignment of IT security with business security. Global TR data aggregation necessitates the development of a security policy for the ‘end-to-end’ environment, which incorporates the control of the use of the data at the TR and at the aggregation mechanism. Data security within the ‘end-to-end’ environment needs to consider technical security as well as environmental security. It is also important for the aggregation mechanism to be able to have preventive practices with respect to security incidents (cyber-attacks, computer crime etc.). Under Option 1, high-reliability tools and procedures for managing centralised access to the data would need to be developed. Moreover, as all the data itself is housed in the aggregation mechanism, it needs to be stored in a secure location.
This model poses a risk in having to implement a powerful security system to ensure the confidentiality of data stored in the central hub and the ability to centralise security checks on the stored data. Under Option 2, data security would need to ensure secure access by the central index to the databases of different TRs and protect the confidentiality of local caches, which could include subsets of actual TR data. In these cases it will be also be necessary to establish secure and reliable network protocols. In the case of direct access from authorities to TRs, bilateral agreements and technical solutions need to be put in place.
The aggregation mechanism has to have a governance function, which would manage and implement the data access rights of different regulators. The governance component itself would need to have a clear audit trail of its own actions as well as need to manage a strong framework of accountability to the regulators. The governance component would need to conduct internal audits to ensure adherence to its operating practices and principles. 6. Chapter 6 – Assessment of Data Aggregation Options This chapter provides an assessment of the pros and cons of each option with respect to criteria and principles discussed in Chapters 3, 4 and 5.
[to be completed after public consultation] Criteria of Assessment On the basis of the analysis presented in Chapters 3, 4 and 5, a list of criteria to assess the different options has been derived from the perspective of uses, legal, data and technology aspects. This list consists of a set of key aspects and requirements for the aggregation mechanism: Uses • Scope of data needed: as recalled in Chapters 1 and 3, to fulfil their mandates, authorities require access to aggregated data at different levels of depth, breadth and identity. The ability of the aggregation mechanism to meet the scope of data needed by authorities in terms of level, breadth and identity will be analysed. • Use flexibility: as noted in Chapter 3, most authorities’ mandates require various forms of aggregated data (e.g.
transaction-level data, or summed by counterparty, 40 . sector, currency, trade venue, date, product, etc.). The complex set of needs of various authorities’ calls for an aggregation mechanism providing flexibility and fitted for evolutionary requests as financial markets and products evolve. Legal • Set-up: given their difference in nature, the various aggregation models do not require the same steps for their creation. The aggregation models are therefore analysed in terms of the legal prerequisites necessary to enable the collection of confidential data from TRs, access to the global aggregation mechanism, governance including for storage of data and information sharing. • Data access ease and usability: given their difference in nature, the aggregation models do not provide the same level of usability to the end-users in terms of the legal steps required to access the data. The aggregation models are therefore analysed in terms of their use once the above set-up prerequisites have been established. Data • Degree of necessary standardisation and harmonisation: Standardisation can be thought of from two different perspectives: (i) the existing use of data standards or the potential to implement the use of common standards; and, (ii) the ability of a model to meet its requirements and manage legal constraints with or without the use of data standards.
In considering the second aspect, it would be important to assess the effectiveness of the model if there are no data standards and the effectiveness under partial standardisation of key identifiers. Additionally, the ability to aggregate and analyse hinges upon data elements having the same meaning and consistent content across all the TRs. Harmonisation is the means of ensuring that data content is interpreted and presented consistently.
For the purpose of assessment, it would also be important to assess the effectiveness of each model under no or partial harmonisation. • Data quality and integrity: in order to ensure a meaningful aggregation and subsequent analysis, the data subject to aggregation should be of high quality. Data quality dimensions considered in this report are completeness, accuracy, timeliness, consistency, accessibility and de-duplication. It is also important for the aggregation mechanism and processes to ensure that the data is protected against unauthorised modification.
Aspects to consider include the ability of the aggregation model to maintain data integrity and the risks to data integrity. Technology • Scalability: the aggregation mechanism should have the ability to scale to accommodate growth in scope and load and in order to manage capacity. Scalability dimensions considered include functional, processing power, data transfer and storage. • Flexibility: the aggregation mechanism should be technologically evolutionary, with flexibility embedded in the system to possibly cater for new aggregation requests. • Resilience: the aggregation mechanism should be resilient to safeguard the interests of its key stakeholders. This depends on several dimensions including the IT security 41 .
of the mechanism, the degree of dependencies on the network stability between a few or multiple points, business continuity arrangements and back-up solutions. This set of criteria is used to assess the strengths and weaknesses of the different aggregation models described in Chapter 1, considering both the level of complexity related to set-up and implementation of the different options, and the need for the solution to be effective in meeting the needs of authorities. [assessment of options to be completed after the public consultation] 7. Chapter 7 – Concluding Assessment This chapter will discuss the conclusion and recommendations of the study from its analysis of the various options for aggregating TR data to assist the FSB, in consultation with CPSS and IOSCO, in its decision on whether to initiate work to develop a global aggregation mechanism and which form of aggregation model should be used. The chapter will explain how the concluding assessment was done and how the conclusions were arrived at. The chapter will list the recommendations, including those that might point to the need for further studies, development of implementation plans as well as unresolved policy areas that might need attention from the FSB, standard setters or different jurisdictions. 42 . SECRETARIAT 22 July 2013 Appendix 1: Feasibility study on approaches to aggregate OTC derivatives data Terms of reference I. Introduction G20 Leaders agreed, as part of their commitments regarding OTC derivatives reforms to be completed by end-2012, that all OTC derivatives contracts should be reported to trade repositories (TRs). The FSB was requested to assess whether implementation of these reforms is sufficient to improve transparency in the derivatives markets, mitigate systemic risk, and protect against market abuse. A good deal of progress has been made in establishing the market infrastructure to support the commitment that all contracts be reported to trade repositories. As noted in the FSB’s April 2013 OTC derivatives progress report 1, at least 18 TRs have been established to date, located across ten jurisdictions, with some intended to operate internationally and others purely domestically. However, further study is needed of how to ensure that the data reported to TRs can be effectively used by authorities, including to identify and mitigate systemic risk, and in particular through enabling the availability of the data in aggregated form. The CPSS-IOSCO consultative report on authorities’ access to TR data, published on 11 April 2013 2, notes that: “With the current structure of TRs, no authority will be able to examine the entire global network of OTCD [OTC derivatives] data at a detailed level.
In addition, it is likely that OTCD data will be held in multiple TRs, requiring some form of aggregation of data to get a comprehensive and accurate view of the global OTC derivatives market and activities. Absent that, the financial stability objectives of the G20 in calling for TRs might not be achieved. In light of these limitations, the opportunity for a centralized or other mechanism to provide global aggregated data, as a complement to the direct access by the different 1 Available at http://www.financialstabilityboard.org/publications/r_130415.pdf 2 Available at http://www.bis.org/publ/cpss108.pdf 43 . authorities to TR held data, probably warrants consideration and further investigation, although beyond the scope of this report 3”. The FSB’s April 2013 OTC derivatives progress report follows up on this suggestion by recommending that further international work should take place on: “the feasibility of a centralised or other mechanism to produce and share global aggregated data, taking into account legal and technical issues and the aggregated TR data that authorities need to fulfil their mandates and to monitor financial stability.” Achieving global aggregation of data may involve several types of aggregation of transaction data: within individual TRs, across TRs and across jurisdictions. To successfully produce and share globally aggregated data, the following elements would need to be addressed to achieve successful aggregation of the TR data to meet regulatory objectives: – definition of the data to be aggregated; – sufficient standardisation of data formats to enable aggregation; – reconciliation of data (for instance, to avoid double-counting and gaps); – establishment of a mechanism(s) for the production of data in aggregated form, supporting the availability of summarised and anonymised data where relevant; and – provision of access to authorities as appropriate. The feasibility study will build upon and take forward the previous work done by other groups, including the January 2012 CPSS-IOSCO report on OTC derivatives data reporting and aggregation requirements 4 and the April 2013 CPSS-IOSCO consultative report on authorities’ access to trade repository data. II. Objectives of the study The feasibility study should set out and analyse the various options for aggregating TR data. For each option, the study should: 3 The CPSS-IOSCO report text added the following here in a footnote: “For performing macro assessments, or supporting provision of data for systemic risk analysis, it is probably worth investigating the feasibility of how a centralised or other mechanism would be able to collect position level and transaction level data from TRs globally and aggregate, summarise and ensure anonymity of the data, subject to applicable local law. The granularity of data could entail breakdowns by jurisdictions and counterparty types. Such a mechanism could support making the data available to all relevant authorities in standardised reports on a regular basis, that would parallel and could learn from, for example, the international financial statistics or the OTCD survey data. It could also facilitate publication of a set of aggregate data.” 4 The January 2012 CPSS-IOSCO report stated: “Work to develop a standard product classification system for OTC derivative products is needed as a first step towards both a system of product identifiers for standardized instruments and an internationally accepted semantic for describing non-standardized instruments.
The Task Force recommends that CPSS-IOSCO or the FSB make a public statement calling for the timely industry-led development, in consultation with authorities, of a standard product classification system that can be used as a common basis for classifying and describing OTC derivative products. Therefore, the Task Force recommends that the FSB direct, in the form and under the leadership the FSB deems most appropriate, further consultation and coordination by financial and data experts, drawn from both authorities and industry, on a timely basis concerning this work.” 44 . • set out the steps that would need to be taken to develop and implement the option, • review the associated (and potentially interdependent) legal and technical issues, and • provide a description of the strengths and weaknesses of the option, taking into account the types of aggregated data that authorities may require and the uses to which the data might be put. The information and technical analysis in the study will provide an important input to assist senior policy-makers in their decision on whether to initiate work to develop a global aggregation mechanism and which form of aggregation model should be used. The options for aggregating TR data to be explored by the study include: 1. A physically centralised model of aggregation. This typically involves a central database (hub) where all the data are collected from TRs, stored and subsequently aggregated within the central database for onward provision to authorities as needed. 2. A logically centralised model of aggregation based on federated (physically decentralised) data collection and storage. Logical centralisation can take a number of forms but the key feature is some type of logical indexing mechanism that enables the use of technology to aggregate data from local TR databases rather than the use of a physically central facility. In this option the underlying transaction data remains in local TR databases and aggregated with the help of the central index (using pointers to local databases).
One variant of logical centralisation is a model where the data is collected and stored locally but, instead of authorities using the logical indexing mechanism themselves to obtain the data from local databases, there is a designated agent that maintains the central index and the platform for responding to requests from authorities. 3. Collection of raw data from local TR databases by individual authorities that then aggregate the information themselves within their own systems. Other aggregation models could also be explored, as the study group considers appropriate. III. Components of the feasibility study The feasibility study should begin with a brief stocktake of the current use of TRs for reporting of transactions, including the number and location of TRs as well as utilized data reporting templates and standards, so as to provide information on the current state of the distribution of TR data that would need to be aggregated. The stocktake should draw wherever possible on existing information on current availability and use of TRs (for instance in the FSB’s OTC derivatives progress reports and the information collected through CPSSIOSCO monitoring of the implementation of PFMIs). The stocktake should also incorporate information (where known) on additional TRs that are planned but not currently operational, and of the likely implications of reporting requirements that are still under development in several jurisdictions for the use of TRs.
This brief stocktake will be needed in order to provide some background on the scale and scope of the aggregation challenge. The study should then address the following interrelated issues for each aggregation option set out above: achievement of the high data quality and consistency that authorities need from aggregated data, including appropriate data standardisation requirements and reconciliation 45 . mechanisms; data access and associated legal issues (including anonymisation of data where relevant); and the analysis of technical, organisational, operational and implementation issues associated with each model. (The ordering and length of description of each issue below is not intended as an indication of the relative importance and amount of the work to be done in the feasibility study.) III.1 Quality and consistency of data including appropriate data standardisation and reconciliation: It is difficult to aggregate data (within a single TR and across TRs nationally or globally) without consistent definition and representation of the data elements to be aggregated. This consistency could be achieved either in the initial reporting of transactions to TRs or through translation of the data into more globally consistent representations during the aggregation process. The study should make an initial analysis of the extent to which aggregation would be possible with the data that will be available under current reporting requirements to TRs. It should identify possible obstacles to the ability to globally aggregate data that may arise from the gaps, inconsistencies or incompatibilities in the data fields, definitions or formats that market participants report to TRs.
Identifying the current scope for aggregation and the obstacles will require an initial stocktaking of data field requirements and definitions and data formatting requirements in multiple jurisdictions, including whether these requirements are codified in law or regulation. The study should also analyse what would constitute a core set of OTC derivatives data elements that, if available in sufficiently standardised form, would enable the aggregation of data among TRs to support regular monitoring as well as other types of analysis by authorities, including of systemic risks. (Such a core data set could then be expanded over time if necessary.) The study should also consider possible approaches to standardising that data. In this regard, the study should draw upon recommendations in the January 2012 and April 2013 CPSS-IOSCO reports and also the work of the FSB’s OTC Derivatives Data Experts Group (ODEG), which considered the data needs of the official sector users of OTC derivatives data. Although the study’s analysis would be directed at standardisation needs in relation to establishment of a global data aggregation mechanism, it may also be relevant to recall a recommendation of the January 2012 report that, in addition to the creation of a system of legal entity identifiers (LEIs), international work be undertaken to develop an international product classification system for OTC derivatives to provide a common basis for describing products.
5 5 The January 2012 CPSS-IOSCO report stated: “Work to develop a standard product classification system for OTC derivative products is needed as a first step towards both a system of product identifiers for standardized instruments and an internationally accepted semantic for describing non-standardized instruments. The Task Force recommends that CPSS-IOSCO or the FSB make a public statement calling for the timely industry-led development, in consultation with authorities, of a standard product classification system that can be used as a common basis for classifying and describing OTC derivative products. Therefore, the Task Force recommends that the FSB direct, in the form and under the leadership the FSB deems most appropriate, further consultation and coordination by financial and data experts, drawn from both authorities and industry, on a timely basis concerning this work.” 46 .
The study should also analyse approaches (whether through data standards, reporting guidelines, or otherwise) to avoid the double-counting of transactions through the aggregation process which might arise where transactions are reported to more than one TR or reported more than once to the same TR (for instance because both counterparties to a transaction separately report the transaction). Among the questions that the study group should address are the following: – Which of the data being reported to TRs needs to be reported and stored in a sufficiently consistent and standardised form that it can be easily and accurately aggregated for financial stability monitoring and other purposes? It could also take into account the potential need in some cases for authorities in their financial stability analysis to combine aggregated OTC derivative data with data (gathered from other sources) on exchange-traded products or cash instruments. – What types of data aggregates might authorities require for financial stability monitoring and other purposes (in light of the recommendations in the CPSS-IOSCO TR Access Report)? – Does the data need to be reported in a globally consistent manner to TRs in the first place to make accurate global aggregation of the data feasible, or is it possible to develop a translation mechanism that will permit the aggregation of data originally provided in different formats? Are there any legal issues related to such translation? Do the answers to these questions differ between the different aggregation models? – How can data standardisation best be achieved (for example by setting international standards for reporting of data to TRs, or by coordination between national authorities)? – What are other elements that need to be standardized to achieve data aggregation such as business rules for producing the data content (e.g. data dictionaries); operational and technology standards for data normalisation/harmonisation, transfer, error handling and reconciliation? – How can data be reconciled, so as to avoid double-counting and gaps in aggregated data? How might aggregation mechanisms address data quality problems that could undermine the usefulness of aggregated data? – Should values be converted to a global currency to allow for cross-currency aggregation? III.2 Data access and associated legal issues for each aggregation model: In considering the feasibility of each aggregation model, legal issues need to be considered, including the legal ability for data to be provided to the aggregating mechanism, as well as the legal ability of the aggregating mechanism to produce and share data with appropriate authorities. In considering these issues, the study group should draw upon the experiences and solutions found by other international data gathering exercises? Among the questions that the study group should address are the following: – What (if any) legal or procedural issues would there be in ensuring data can be sent from TRs into the aggregating mechanism? What requirements may this put on an 47 . aggregating mechanism to ensure data security is maintained? How do these legal issues differ between the different options for aggregating mechanisms? – What legal and procedural issues would need to be addressed with regard to the production and sharing of aggregated data under each of the models? How might privacy and confidentiality issues and any other restrictions affecting authorities’ access to TR data, such as indemnification requirements, affect the modalities for making aggregated data available under each of the options, either in terms of passing on aggregated data to a hub or providing the information to authorities? 6 – Are these issues affected by whether the data are obtained by domestic or foreign authorities directly from TRs, from a hub, or via other authorities? How do those issues differ according to the scope of aggregation (for example, at a national or cross-border level or the form in which the data is being provided, e.g. anonymised or summarised)? – Are there additional legal issues in cases where authorities may also require access the original data before aggregation, or may require access in a form that gives them flexibility to able to aggregate it in different ways (for instance by subsets of products or market participants)? – What types of agreements could be needed to support each aggregation model? To what extent are data access and sharing needs covered by existing information sharing agreements, or are further agreements likely to be needed? How can questions of data security be dealt with? – What are important preconditions in each jurisdiction related to data provision and use (e.g., multilateral or bilateral MoUs)? How would legal prohibitions, limitations, or preconditions affect the structure of the aggregation mechanism? How can such legal prohibitions, limitation, or preconditions be overcome via different operational solutions? – Are there circumstances in which, for legal reasons, data may need to be aggregated first at a national level before cross-border aggregation takes place? III.3 Analysis of technical, organisational and operational issues of each aggregation model: For each of the possible approaches to providing globally aggregated TR data to authorities, the study should examine the operational implications and issues, taking into consideration: – existing TR infrastructure and data reporting standards; – data privacy and confidentiality considerations, building on the work already conducted on these issues in the area of OTC derivatives and bearing in mind the different categories of data users amongst authorities; 6 Issues arising from current privacy and confidentiality restrictions on the reporting of data to TR and on the reporting of TR data to authorities are surveyed in the FSB’s April 2013 OTC derivatives progress report. This feasibility study should consider any issues arising for the aggregation model from such restrictions. 48 . – local languages and variations in existing national approaches to the representation of trades; – the governance of the mechanism; including the relationship with overseers of TRs; – important practical aspects, such as time to implementation, technological requirements, operational reliability, adaptability and cost efficiency. IV. Composition of the feasibility study group The feasibility study group is to be co-chaired by experts from member organisations of CPSS and IOSCO. The composition of the study group is to be ad hoc including, in addition to experts from CPSS and IOSCO members, other experts from organisations not represented in these bodies that have roles in macroprudential and microprudential surveillance and supervision and the FSB Secretariat. The group should include a balanced representation of a range of expertise, covering aspects such as: – data fields and formats; – the potential needs of and uses by authorities of aggregated data; – legal and regulatory considerations; – IT and other technical issues. At the same time, the number of members should be limited to approximately 20 people, to enable the study group to work expediently. The Secretariat for the study group will comprise members of the CPSS, FSB and IOSCO Secretariats. The tight timeline and the potential interrelationships between data and legal issues imply that these two sets of issues should be explored in parallel. The study group should therefore set up two subgroups to consider respectively the technical data issues and the data access and legal issues.
(This would be similar to the approach taken in the FSB’s Data Gaps Implementation Group that is implementing a common data template for G-SIFIs.) These groups should coordinate closely in real time, through having some members in common, common secretariats and sharing of working papers, to ensure that interrelationships between the two sets of issues are taken account of. They should involve additional experts beyond the study group members as needed. The study group may also set up other workstreams in specific areas as it sees fit, which may involve additional experts in specific areas. V. Schedule and deliverables The group will need to work under an accelerated timeline, given the importance of rapid completion of the G20 reforms and effective use of TR data by authorities. The group should provide progress reports on the status of the work to the FSB, and for information to CPSS and IOSCO, including an interim report before end-September.
The group should prepare a 49 . draft report by mid-January 2014 for review and approval by the FSB, with a view to requesting public feedback beginning no later than mid-February 2014. The final report should be provided to the FSB no later than end-May 2014 and will subsequently be published. The FSB, in consultation with CPSS and IOSCO, will then make a decision on whether to initiate work to develop a global aggregation mechanism and, if so, according to which type of aggregation model and which additional policy actions may be needed to address obstacles. In taking forward the work, the group should engage with market participants and market infrastructure providers, having regard to geographical balance as well as with firms in the non-financial sector that have had successful experience in building functioning uniform global data infrastructure systems. As part of this engagement, the group should consider whether to host a workshop to discuss each aggregation model, its pros and cons and implementation approaches as part of its analysis. 50 . OFFO Appendix 2: Summary of the outreach workshop FSB Aggregation Feasibility Study Group (AFSG) outreach workshop Summary of the meeting in Basel 13 November 2013 The FSB AFSG Industry Workshop was conducted in Basel, Switzerland on November 13, 2013. The purpose of the workshop was for the AFSG membership to understand industry perspectives, approaches and practices to aggregation and apply those to the development and assessment of the different options for Trade Repositories (TR) aggregation being considered by the group following the FSB mandate. I. Opening remarks The co-chairs of the FSB feasibility study group on approaches to aggregate OTC derivatives data, Mr Benoît Cœuré (ECB) and Mr John Rogers (US CFTC) welcomed the outreach workshop participants. They noted that the purpose of the event was to learn about various options of the data aggregation from different aspects. The specific objective of the workshop was to assist the group in its work to identify the pros and cons of mentioned three options for aggregation: 1. A physically centralised model of aggregation. 2. A logically centralised model of aggregation based on federated (physically decentralised) data collection and storage. 3. Collection of raw data from local TR databases by individual authorities that then aggregate the information themselves within their own systems. The co-chairs indicated that the workshop would address both technical and legal issues in relation to the implementation of the alternative options, and the AFSG had invited attendance of experts with expertise in the range of issues involved, including data, IT and legal issues. II. Panels to discuss current approaches to data aggregation (inside and outside the financial sector) A. A physically centralised model of aggregation Panellists: Trade Repository Limited, LSE, SAMA-TR The panel on physically centralised model of aggregation focused on how the model would be defined, what the pros and cons are and what the potential hurdles for implementation are and how to overcome them.
The panellists presented their experiences and advise on the aspects to consider in developing and assessing such a model. 51 . The current data aggregation challenge was presented where aggregated number of reports is not equal to the market’s exposure. That creates an issue of how the data aggregated from TRs actually allows regulators to meet various regulatory needs. The objectives of instrument/product data were enumerated in order to achieve regulatory data use: global scale, multiple purpose, automated analysis, automated aggregation, cross market focus. The participants suggested that a semantic representation using a concatenation of standardised building blocks can be helpful to overcome the global data aggregation challenge.
It was noted that with source data (i.e. data that can be aggregated) and timely additive partial composites, the meaningful observations of changes to market flows and exposures are readily available just days after trades are done and that even with limited coverage this enables better market oversight and systemic risk analysis and management. Participants also stated that before going into selection of aggregation models the following questions need to be answered: Are all the current derivative reporting regulations compatible? How do you ensure data is not duplicated? How is access to data governed and approved? What can be done to ensure the consistency of the data? What is being aggregated? Participants emphasised that governance is one of key dimensions of a physically centralised model. It was also mentioned that when implementing a physically centralised model on the local level, the unavailability of standardised taxonomies for the contracts was a challenge. Consequently, the TRs had to develop standards and shared them among reporting entities. That facilitated the ability to aggregate and compare the reported data. Participants also explained their experiences in implementing and developing standards that would assist in the harmonisation and description of complex OTC derivatives data which would in turn assist aggregation efforts. The participants also explained their experiences and challenges in implementing the model under different circumstances including management of stakeholders, technical planning, project planning, access governance, project management as well as technical implementation. B. A logically centralised model of aggregation based on federated approach Panellists: ANNA, GS1, Quartet FS, DTCC, Denodo The session focused on the logically centralised model of aggregation based on a federated data collection and storage.
The objective was to answer the following questions: What is the logically centralised model? How can it be implemented? What are the obstacles and how can they be overcome? Participants made it clear that several variants might exist under the logically centralised model label. While such model is in essence characterised by the combination of data remaining stored in local repositories and the existence of an index, the scope of the data contained in that index may vary widely. On one extreme the index may be populated with only a list of identifiers with pointers to the local repositories.
In such a scenario, the index would not store actual data but only references. However, when the data get complex - and also depending on the complexity of the queries - the index would have to store (cache) some data for the mechanism to produce the expected outcome. In any case, it is a key that the index can be trusted and is thus properly governed.
As an overall consequence, participants considered that a logically centralised model can mitigate some legal issues 52 . compared with a centralised model when processed data are confidential, but the extent to which it could achieve this would ultimately depend on the data held in the index and the nature and of oversight/supervision or governance of the index operator. In the context of financial transactions, participants considered whether it was likely that the aggregation mechanism would require more data held in some version of a centralised unit in order to perform indexing. In this respect, participants underscored that the nature of the data processed - whether public as in the LEI framework or private and confidential as data held in TRs - would be a key matter to bear in mind. Some participants opined that the logically centralised model might not be the most efficient one for complex queries. They also highlighted the need to make the aggregation mechanism flexible and scalable. For example, participants made clear that the mechanism should be flexible regarding the incorporation of new queries and further (new established) TRs.
Some participants stated that they would not recommend pre-aggregation of data and advised that the aggregation mechanism should use the raw transactional data to produce the aggregated outcome of good quality. More generally, and beyond the issue of the model to be adopted, participants noted that a clear identification of the objective of the aggregation with a distinction between local regulatory objectives and global ones would help to identify the granularity of the data needed as well as governance model. However, they admitted that the use of raw data raises a number of the issues on confidentiality and volume/cost issues that should not be ignored. In addition, they opined that the use of raw data may also increase the expectations on the role of the index and its operator, or at least of the rules that entities using the index should follow (to ensure harmonised aggregation). Some participants highlighted that the distinction between the content of the data to be captured and the move of the data among the interested parties (”choreography”) is an important feature of a logically centralised model.
In order for the model to work and to provide good-quality data, the participants felt that content has to be clearly defined and be the same among the actors of the model regardless of the choreography, while choreography might vary based on circumstances. In contrast, there might be different styles of choreography (where the data reside, when and how they move between partners, regulators, repositories) with a need to be able to change the choreography to match varying processes. Regarding the content, and in the context of financial transactions, participants observed that product scope varies by jurisdictions, including the definition of derivative contracts. Therefore, they expressed that there is a need for regulators to look at open sources and standards supported by industry stakeholders - and to promote globally recognised identifiers wherever possible. Participants felt that adequate procedures (criteria for membership, regular (standardised) report) need to be in place to generate trust. Finally, participants mentioned several additional benefits of the logically centralised model, in terms of scalability, tailoring to local needs and cost reduction through competition, but also warned that many initiatives have failed due to costs. 53 . C. Data collection and aggregation by users from local sources Panellists: ACTUS, NSD, ICE, Bloomberg, NOAATS, CME Group Panellists presented their views on data collection and aggregation by users from local sources and potentially at local level. It was noted that the objective of aggregation is to get meaningful financial analytical information. Simple aggregation of disparate financial instruments does not support this objective because there is no common metric to support such aggregation. It is akin to trying to add apples and oranges.
Meaningful financial analytical information is derived from the ability to understand how changes in risk factors affect value, income, liquidity, and stress tests. Such analyses start with the ability to represent how changes in risk factors affect the cash flows associated with individual financial contracts. The example of algorithmic contract types unified standards (ACTUS) was introduced to solve this problem.
It is being developed to generate the common metric of state contingent cash flows for all financial contracts. Such state contingent cash flows are the starting point for a broad range of financial analyses. These analysis results can then be aggregated for any size pool of financial obligations -- portfolios, single institutions, individual markets, or the financial system -- to yield meaningful financial analytical information. Participants expressed the view that the following core principles for the TRs needed to be introduced to guide the feasibility analysis: (a) transparent and high standards governance; (b) minimal operational processing; and, (c) adherence to current and future rules of regulatory authorities.
That would require common data on counterparties; products, trades, venue(s) of execution, price, quantity, Central Counterparties (CCPs) at minimum. For the purpose of data aggregation the TRs face a number of challenges that need to be addressed such as collection of accurate data, clarity on fields being reported to TRs; data harmonisation where there is a lack of consistency among TRs on the interpretation of data requirements. Data security was emphasised as a key consideration. Participants also described the common ETL (extract/transform/load) approach that could be applied for data aggregation: (a) extraction of external data from sources; (b) transformation/conversion of external data into internal target format where data needs to be normalised so it can be aggregated and accurate meaning can be inferred from it; and, (c) finally load of useable data to target database.
Different depths of access were introduced for different data types to achieve aggregation purposes. Participants noted that local/federated type data aggregation might work. Data sharing between authorities could be done using standard framework under reciprocal agreement – however legal issues would need to be addressed in terms of what can be shared across jurisdictions.
Different views were presented on what model is more expensive for implementation and long-run maintenance. Panellists emphasised that while legal and technical issues on collecting transaction level data by each local TR could be addressed with relatively less effort, global collection and aggregation of OTC derivatives data could raise many issues between countries and various stakeholders within each country depending on the access level. As a practical way forward, equal accessibility by every country to the data was suggested. In this context accessibility means literal ability to access global data and capability of an authority to achieve its goal by using the data.
The participants felt that UPI system standard was vital for data aggregation. 54 . III. Data considerations Panellists: FIBO, FIX, FpML, ISO The panel on Data Consideration discussed matters related to data and data standards and how to leverage them for aggregation. Participants noted a number of times that data standardisation was a key tool for data aggregation. They also noted that the focus should be on standardisation of content rather than on formats. Participants noted that the biggest standards gap is in the area of financial language and unambiguous shared meaning (definitions).
They also noted that existing standards used by (participants/TRs/regulators) can be leveraged if mapped to a common meaning. Panellists also elaborated on the difference between semantics and syntax of standards. They noted that terminology plays a major role in understanding semantics and that a common terminology with definitions and ‘translations’ would be helpful here. They further noted that without standards for counterparties, instruments and trades, it would be hard to make quick progress in data aggregation.
Counterparties and instruments might be subject to a hierarchical structure and relationships between entities may be of interest when aggregating data. Participants stated that reporting of aggregated data requires an upfront and detailed specification, and noted that if such a specification is ambiguous, it might result in a lack of harmonisation and, worse, in misaggregation and thus unreliable data. Participants stated that reporting of transaction level data is easier as it is primarily about passing through data from market participants yet they noted that it raises more confidentiality and thus governance issues. Participants also introduced their ideas about structure of UTIs and UPIs.
In particular, they noted that UTI generation and communication should occur at earliest possible point in trade flow. One of the suggestions was to use a prefix in UTI construct focused on utilizing the CFTC USI namespace in the construction of the UTIs. With respect of to the UPI, one of the suggestions was to use ISDA OTC taxonomy.
Under this model, they noted that the ISDA Asset Class Implementation Groups and Steering Committees proposed and approved this governance structure. It was also suggested that no country- specific IDs should be used and that only global codes, such as the LEI, should be used. It was also noted that there is a need for collaboration between regulators and endorsement by regulators of the development of a unique global trade and product identifiers.
Otherwise, we risk having multiple identifiers, which defeat part of the purpose and will make the work of aggregation more difficult. Furthermore, participants suggested that existing identification and classification schemes should be used as far as possible. They noted the experience of common data dictionaries under ISO 20022 (ISO 20022 “Investment Roadmap” integrated FIX, FpML, ISO (MT/MX) and XBRL into a common framework). It was also noted that only open- access and nonproprietary standards should be used in order to avoid competition issues and not to discriminate against smaller operators. 55 .
IV. A. Legal considerations in data aggregation Panellists: ISDA, STET, DTCC, BM&FBOVESPA The session focused on the potential legal issues that might arise from the data aggregation framework. Firstly, participants pointed out existing legal issues such as privacy and confidentiality, intellectual property, indemnification, and data access. An example of the centralised hub for derivatives introduced in Brazil (due to their 3 TRs) was presented to participants.
The Brazilian system also includes valuation data and the registration in a TR is a condition for legal validity of the contracts. With regard to data aggregation schemes, participants asked for more clarity on which authorities have access to what kinds of data and for what mandate. In order for authorities to share the data, while ensuring the data security/protection, participants suggested that authorities might want to consider establishing a framework of multilateral MOU, possibly leveraging MoUs such as IOSCO Multilateral MOU. Though participants noted that anonymisation could help to solve the confidentiality issue, they questioned how authorities could aggregate and properly use such data for assessing and monitoring systemic risk and monitoring financial markets in general without names or unique identifiers. Also they noted that the method of anonymisation needs to be consistent amongst TRs.
One of the proposals was to establish a harmonised model to regulators as they bear a general duty to keep data confidential while ensuring regulators get access to the data appropriate to their mandates. This could also be extended to the public, in aggregate form (data dissemination duty). Some participants felt that legal issues might be less complicated if the data could be aggregated and then distributed to authorities than a case where providing authorities are provided with direct access to detailed data however others disagreed with the position.
Participants also noted that different jurisdictions have different requirements for OTC derivatives reporting (e.g. US position reporting versus EU reporting of contracts, the latter putting the responsibility to calculate positions on the TRs themselves). Some participants noted that the data level of detailed data depends on the purpose of data collection and suggested that if the purpose of data aggregation is to have general view of the OTC derivatives markets, classification such as banks, hedge funds, pension funds etc. might suffice to support such an objective. Regarding individual clients (natural persons), participants pointed out that reporting requirements vary from country to country.
They noted, for example that, in Japan, in a case where counterparty is not a bank, it is not necessary to report specific names but only classification as ‘client’. The participants argued that, given the large volumes of data, it might be enough to collect and analyse the data of relatively large reporting firms (e.g., top-ten firms and top-ten counterparties). They opined that if authorities observed any potential risk, then the relevant national authorities could have access to the raw data to analyse at a deeper level. In that sense, collecting data from large entities would possibly satisfy the need/objective to analyse the systemic risk. Participants noted that generally there exists no legal intellectual property (IP) rights on raw data but data aggregated by TRs could be protected pursuant to the relevant IP rules and laws. 56 .
The term 'ownership' was discussed regarding data access rights. One commenter suggested that TRs only have the rights to use the data as described by regulations the legal and contractual rules under which they operate. This is an important factor on disclosure of data as TRs do not own the data they received and are bound by a legal obligation of confidentiality towards their clients by its participants and under regulation. Participants recalled that authorities have access to the data held at TRs in their jurisdictions, for their specific mandates. In addition, in the cross-border context, authorities have access to the data to fulfil their mandates based on the CPSS-IOSCO Access Report.
In these cases, confidentiality is still an issue since the data needs to be kept secure (in authorities’ domain). IV. B. Technology considerations Panellists: Denodo, PRMIA, Sapient, TriOptima In this section participants focused on technology considerations for analysis of data aggregation models. Among technical dimensions, data standards, aggregation methodology and system architecture were outlined.
On the business and policy dimensions participants discussed commercial incentives, practical reality and political will as well as trust. Participants also noted the overlapping dimension of the access choreography that needs to be carefully structured. The docking model of financial data compression was introduced where the transaction aggregation systems provide access via extraction, transformation and load to granular data that is being aggregated via tuneable, multi-dimensional processor. Participants introduced the idea of service centres which harvest and manage data from various repositories. It was noted that the challenge of complex structured deals would be addressed by the opportunity of visual data navigation tools.
Participants emphasised that data size is not a real issue but data standardisation, cost and complexity are the issues to focus on. Participants introduced data virtualisation. This approach decouples data complexities from the business logic; defines canonical data models for business units; utilises central governance for security and data lineage, provides data on demand either via cache or scheduled batch; allows reuse of models which are easy to transform, combine and change data, reduces replication costs; and integrates with existing tools. Participants also discussed the concept of exposure and repository reconciliation. They identified five important targets when discussing technical considerations and conceptual architecture: scalability, availability, confidentiality, integrity and sustainability. Participants made a distinction between two data aggregation models from the standpoint of anticipated analysis - reactive approach versus a proactive approach.
In reactive approach analysis is undertaken when triggers locally require an extended scope of analysis. Participants felt that from this standpoint it reduces resilience requirements as system uptimes are required for retrospective forensic analyses rather than real time monitoring. Participants discussed whether repositories’ primary purpose is for storage and forensic analysis. Participants stated that for valuable forensic analysis, a complete non-aggregated record is preferred with low data sharing restrictions. On the other hand, proactive approach provides for configured analytics trending on data to highlight potential risks.
Here resilience requirements are increased as analytical success is dependent on robust data delivery. Participants stated that in this case, the primary purpose is to highlight trends of concern. 57 . Participants noted that at the same time data sharing and aggregation can be restricted to satisfy extra territorial restrictions and harmonised canned reports required to push trend and analytics data to regulators. V. Summary of takeaways from subgroup discussions and closing remarks The co-chairs thanked the workshop participants for their insights and professional opinions which would be a useful basis for the FSB group AFSG analysis. They encouraged participants to provide further comments on the consultative report of the group to be released in February 2014 as a continued engagement in the public-private consultation process. 58 . List of private sector participants for the FSB outreach workshop on approaches to aggregate OTC derivatives Basel 13 November 2013 Bloomberg L.P. Ravi Sawhney Head of Fixed Income Credit Trading BM&FBOVESPA Marcelo Wilk OTC Operations Officer The Central Securities Depository Leszek Kolakowski Vice Director, Strategy and Business Development of Poland (KDPW S.A.) Department Kinga Pelka Specialist, Trade Repository Department CME Group Jonathan Thursby President, CME Swap Data Repository Denodo Technologies Gary Baverstock Regional Director, Northern Europe FIX - Deutsche Börse AG Hanno Klein Senior Vice President DTCC Marisol Collazo DerivSERV FIBO - EDM Council, Inc Michael Atkin Managing Director Fincore Ltd Soeren Christensen CEO George Washington Law School University Navin Beekarry Researcher, Lecturer GS1 Kenneth Traub Standards Strategy Consultant Intercontinental Exchange Kanan Barot Director, Ice Trade Vault Europe ISO - Investment Management David Broadway Senior Technical Adviser Association 59 . ISDA Karel Engelen Director, Global Head Technology Solutions ISDA - Deutsche Bank Stuart McClymont ISDA data and reporting steering committee KOSCOM He Young Jun Assistant Manager, Global Business Department Gi Young Song Assistant Manager, System Department LCH.Clearnet. Ltd Richard Pearce Business Change Manager, SwapClear London Stock Exchange Group James Crow Head of Product Solutions & Development (LSEG) Neil Jones Product Solutions Architect ANNA - Malta Stock Exchange Stephanie Galea Senior Manager, Compliance & Market Operations Mizuho Bank Ltd Satoru Imabayashi SVP and Head of Planning, Market Coordination Div. National Settlement Depository Pavel Solovyev Head of Trade Repository Development NOA ATS Kibong Moon CEO Nomura Kieron O’Rourke Global Head of OTC Services Project ACTUS Allan Mendelowitz Strategic Adviser QUARTET FS Catherine Peyrot Senior Sales Executive David Cassonnet Program Director REGIS-TR Mari-Carmen Mochon Project Manager 60 . RTS Alexandra Kotelnikova Chief Expert, Regulatory Support Department Sapient Global Markets Cian O’Braonain Regulatory Reporting Practice Global Lead Peter Newton Senior Manager, Markets Infrastructure Initiatives Saudi Arabian Monetary Agency Abdulaziz Alsenan Project Manager, General Department of Payment Systems Mohammed Al Hossaini General Department of Payment Systems STET Fabienne Pirotte Legal Counsel Sumitomo Mitsui Banking Corporation Kenji Aono Deputy General Manager, Corporate Risk Management Dept SWIFT Yves Bontemps Head of Standards R&D PRMIA - Tahoe Blue Jefferson Braswell CEO, Founding Partner The Trade Repository Ltd Marcelle Kress von Wendland CEO Traiana Ltd Mark Holmes Programme Manager TriOptima Henrik Nilsson Head of Business Development 61 . OFFO Appendix 3: Extract from the Access Report (Table 6.2) Assessing systemic risk (examining size, concentration, interconnectedness, structure) Evaluating derivatives for mandatory clearing determinations and monitoring compliance with such determinations Evaluating derivatives for mandatory trading determinations and monitoring compliance with such determinations Definition An authority with a mandate to monitor a financial system and to identify emerging risks An authority that has a mandate to evaluate OTCD for mandatory clearing determinations and monitoring its implementation An authority that has a mandate to evaluate OTCD for mandatory trading determinations and monitoring its implementation An entity that has a mandate to foster and support financial stability globally An authority that has a mandate to conduct market surveillance and enforcement Typical depth of data required Transaction-level Transaction-level Transaction-level Position-level Transaction-level Typical breadth of data required All counterparties (1) Any transactions in which one of the counterparties is within its legal jurisdiction and (2) all transactions on the underliers (i) within its legal jurisdiction (whether the counterparties are in the jurisdiction or not), (ii) for which the authority considers making or makes a mandatory clearing determination, or (iii) any transactions involving the same type of OTCD contract as the one being evaluated (whether the counterparties or underliers are in the jurisdiction or not) (1) Any transactions in which one of the counterparties is within its legal jurisdiction and all (2) transactions on the underliers (i) within its legal jurisdiction (whether the counterparties are in the jurisdiction or not) or (ii) for which the authority must make a mandatory trading determination All counterparties Any transactions for counterparties in its legal jurisdiction as well as branches or subsidiaries of these counterparties which may be in other jurisdictions, and all transactions on the underliers within its legal jurisdiction (whether the counterparties are in the jurisdiction or not) Identity Named data for counterparties and underliers within their legal jurisdiction. Anonymised data for other counterparties Anonymised counterparties and named data where named data are required for evaluating determinations; named data for monitoring compliance with such determinations Anonymised counterparties and named data where named data are required for evaluating determinations; named data for monitoring compliance with such determinations Anonymised Named data 62 General macro assessment Conducting market surveillance and enforcement . Registering and regulating market participants and supervising market participants with respect to business conduct and compliance with regulatory requirements Prudentially supervising financial institutions Supervising/ overseeing exchanges, organised markets and organised trading platforms Regulating, overseeing and supervising payment or settlement systems Regulating, overseeing and supervising CCPs Regulating, overseeing and supervising TRs Definition An authority that has a mandate to supervise market participants. An authority that has a mandate to supervise and regulate or to monitor and conduct surveillance on the financial institution An authority that has a mandate to supervise exchanges, organised markets and organised trading platforms An authority that has a mandate to oversee a payment or a settlement system An authority that has a mandate to supervise or oversee a CCP An authority that has a mandate to supervise a TR Typical depth of data required Transaction-level Transaction-level Transaction-level Transaction-level Transaction-level Transaction-level Typical breadth of data required Transactions in which one of the counterparties, whether registered or not, is within its legal jurisdiction, or in which one of the counterparties engages in OTCD transactions with, or whose OTCD transactions are guaranteed by, an entity within its legal jurisdiction (whether the counterparties are in the jurisdiction or not) Transactions in which one of the counterparties is a consolidated organisation whose parent is supervised by the authority, including all subsidiaries, domestic or foreign, of the entity Any transactions traded on an exchange, organised market or organised trading platform supervised by the authority Any transactions settled by a payment or settlement system overseen by the authority Any transactions that are cleared by a CCP supervised or overseen by the authority Any transactions reported to the TR Identity Named data Named data Named data Anonymised transactionlevel data as a general rule, but named positionlevel data for the counterparties of the central bank and where investigation of suspicious activity is needed. Named data Named data 63 . Planning and conducting resolution activities Managing currency policy Implementing monetary policy Lender of last resort function Definition An authority that has a mandate to resolve financial institutions An authority in its function as monetary policy authority An authority in its function to implement monetary policy An authority in its function as possible lender of last resort Typical depth of data required Transaction-level Transaction-level (Participants within legal jurisdiction), aggregate-level (all participants for underliers denominated in its currency) Aggregate-level Position-level Typical breadth of data required Any transactions in which one of the counterparties is the entity subject to resolution or a domestic or foreign affiliate Any transactions that specify settlement in that currency, including transactions for which that currency is one of two or more specified settlement currencies Any transactions for participants within a central bank’s legal jurisdiction or underliers denominated in a currency for which the central bank is the issuer Any transactions for which a named institution is a counterparty Identity Named data Anonymised Anonymised Named data 64 . OFFO Appendix 4: Data Elements Data elements needed to perform queries for various regulatory purposes can be classified in various ways. The list of data fields depends on the mandate of the user and shall be adapted according to the specification and particular type of the aggregation system. The diagram below shows different examples of data elements that may be used by users to perform a request. Another list of fields data elements (below) is intended to allow the user to describe the form of the result expected This includes the specification of expected data elements and of operations to be performed on the data, such as summing or counting. Depending on their mandate, some users will have limited ability to define the form of the result, for instance some of them might be obliged to perform summation over specific data elements. LEI Counterparties LEI LEI CCP LEI Range (if transaction-level) Date Final beneficiary Executing broker, clearing broker Participants Sector or counterparty type (ex.
non-financial counterparty) Between XX and XX Snapshot (if position-level) All open contracts at date XX Type of date: execution, settlement, clearing, modification of contract, termination UPI (or range of UPIs) Product Underlying Delivery type Master agreement Status Open: Y/N Cleared: Y/N From the standpoint of a user, the requests and the results need to be independent from the specific implementation of the system. The different requests described here could be performed under any of the options discussed in this report. 65 . Net/gross Position Portfolio/entity level Type: price-forming trade, intragroup… Individual data Field of the table Transaction Anonymous or not Duplicates allowed: Y/N Count Aggregation/ operations Sum For currencies: conversion into one currency (accoridng to conversion rules) or sub-results according to the various currencies Set operations Append, difference, join… 66 . Appendix 5: Glossary of Terms and Abbreviations Access Report August 2013 CPSS-IOSCO report on authorities’ access to TR data. AFSG Aggregation Feasibility Study Group Aggregated Data Data that have been collected together, but may or may not have been summed; the data could instead be available at transaction-level or position-level. Aggregate-Level Data Data that have been summed according to a certain categorisation, so that the data no longer refer to uniquely identifiable transactions. Aggregation Mechanism Mechanism designed for aggregating data. Aggregation Model Three broad aggregation models are discussed in the report: Option 1 - a physically centralised model; Option 2 - a logically centralised model; and Option 3 - the collection and aggregation by authorities themselves of raw data from trade repositories. See Section 1.3 for more details. Anonymised Data Data from which the counterparty name or other identifier have been removed. Access Rules Rules that determine which authorities have access to which information according to their mandate and confidentiality restrictions in the use of data. BIS Bank for International Settlements BCM Business Continuity Management CCP Central Counterparty Child-Trades Series of smaller orders, as opposed to “parent” or larger orders. CFI Classification of Financial Instruments CPSS Committee on Payment and Settlement Systems CDs Credit Default Swaps Data aggregation The organisation of data for a particular purpose, i.e., the compilation of data based on one or more criteria. See Section 1.5 for a more detailed discussion. 67 . Data Report January 2012 CPSS-IOSCO report on OTC derivatives data reporting and aggregation requirements. EMIR European Market Infrastructure EU European Union FMIs Financial Market Infrastructures FSB Financial Stability Board Flow Event An event such as a new trade, an amendment or assignment. G20 Group of Twenty GLEIF Global LEI Foundation G-SIBs Global Systemically Important Banks HGG Hub Governance Group. Oversees the pooling and sharing of information and is responsible for all governance aspects of the multilateral arrangement for the International Data Hub. ID Identification of underlying instrument International Data Hub An international framework that supports improved collection and sharing of information on linkages between global systemically important financial institutions and their exposures to sectors and national markets. See Box 3 of the report. IOSCO International Organization of Securities Commissions ISO International Organization for Standardization ISDA International Swaps and Derivatives Association IT Information Technology LEI Legal Entity Identifier: An LEI comprises a unique machine readable code identifying the entity, that points to a set of key reference data relating to the entity, such as the name, address, etc. (See FSB “A Global Legal Entity Identifier for Financial Markets” Report). MoU Memorandum of Understanding OTC Over-the-Counter 68 .
RED Codes Reference Entity Data Base Codes: Unique alphanumeric codes assigned to all reference entities and reference obligations ROC Regulatory Oversight Committee for the global LEI system. TR Trade Repository: TRs are entities that maintain a centralised electronic record (database) of OTC derivatives transaction data. UPI Unique Product Identifier: A product classification system that would provide each individual financial product with a unique code. UTI Unique Transaction Identifier: A transaction classification system that would provide each individual transaction with a unique code. 69 . Appendix 6: Members of the Aggregation Feasibility Study Group and other contributors to the report Co-chairs: Benoît Coeuré European Central Bank John Rogers US Commodity Futures Trading Commission Australia Jennifer Dolphin Australian Securities and Investment Commission Brazil Sergio Ricardo Silva Schreiner Securities and Exchange Commission Canada Joshua Slive Bank of Canada Andre Usche Bank of Canada Shaun Olson Ontario Securities Commission Jean-Philip Villeneuve Québec AMF China Shujing Li China Securities Regulatory Commission Zhu Pei China Securities Regulatory Commission France Priscille Schmitz Banque de France Olivier Jaudoin Banque de France Yann Marin Banque de France Sébastien Massart Autorité des Marchés Financiers Germany Sören Friedrich Deutsche Bundesbank 70 . Hong Kong Colin Pou Hong Kong Monetary Authority Pansy Pang Hong Kong Monetary Authority India Sudarsana Sahoo Reserve Bank of India Italy Carlo Bertucci Banca d’Italia Japan Osamu Yoshida Financial Services Agency Hiroyasu Horimoto Financial Services Agency Shoji Furukawa Financial Services Agency Korea Namjin Ma Bank of Korea Netherlands Rien Jeuken De Nederlandsche Bank Russia Philipp Ponin Central Bank of the Russian Federation Saudi Arabia Abdulmalik Al-Sheikh Saudi Arabian Monetary Agency South Africa Marcel de Vries South African Reserve Bank Sweden Loredana Sinko Riksbank Malin Alpen Riksbank Switzerland Patrick Winistoerfer Financial Market Supervisory Authority UK Nick Vause Bank of England Anne Wetherilt Bank of England John Tanner Financial Conduct Authority 71 . US Srinivas Bangarbale Commodity Futures Trading Commission James Corley Commodity Futures Trading Commission Cornelius Crowley Department of the Treasury Angela O’Connor Federal Reserve Bank of New York Janine Tramontana Federal Reserve Bank of New York Kathryn Chen Federal Reserve Bank of New York Celso Brunetti Federal Reserve Board European Central Bank (ECB) Simonetta Rosati Karine Themejian Daniela Russo Roland Straub European Commission Mariel Jakubowicz Julien Jardelot European Securities and Markets Authority International Organization of Securities Commissions (IOSCO) Committee on Payment and Settlement Systems (CPSS) Frederico Alcantara FSB Secretariat Rupert Thorne Irina Leonova Tajinder Singh Yukako Fujioka Klaus Martin Löber Philippe Troussard 72 . Appendix 7: List of References CPSS-IOSCO: Authorities' access to trade repository data (“Access Report”), August 2013. CPSS/IOSCO: Report on OTC derivatives data reporting and aggregation requirements (“Data Report”), January 2012. FSB: A Global Legal Entity Identifier for Financial Markets, 8 June 2012 FSB: OTC Derivatives Market Reforms: Fifth Progress Report on Implementation, 15 April 2013 FSB: OTC Derivatives Market Reforms: Sixth Progress Report on Implementation, 2 September 2013 IMF staff and FSB Secretariat: The Financial Crisis and Information Gaps - Report to the G-20 Finance Ministers and Central Bank Governors, October 29, 2009 International Organization for Standardization: ISO 22301:2012 Societal security -- Business continuity management systems --- Requirements Regulatory Oversight Committee: Charter of the Regulatory Oversight Committee for the Global Legal Entity Identifier System, 5 November 2012 73 .





